От Naive RAG до ReAct-агента: как мы строили корпоративного AI-помощника на open-source моделях (часть 2)
chestny_znak 36 минут назад От Naive RAG до ReAct-агента: как мы строили корпоративного AI-помощника на open-source моделях (часть 2) Простой 17 мин 1.6K Блог компании 43Tech Искусственный интеллект Open source *...
GPT-5.6 31 Temmuz 2026'da yayınlanacak mı?
Вот важная новость с фронта ИИ: chestny_znak 36 минут назад От Naive RAG до ReAct-агента: как мы строили корпоративного AI-помощника на open-source моделях (часть 2) Простой 17 мин 1. 6K Блог компании 43Tech Искусственный интеллект Open source * Natural Language Processing * Обзор Привет, Хабр! Меня зовут Саша, я — старший AI-инженер в Лаборатории искусственного интеллекта «Честного знака».
Наша команда развивает «Честного помощника» — мультиагентную LLM-систему для обработки документов, поиска информации по Confluence, Jira, GitLab и генерации текстов. Главная цель команды — повышать эффективность и качество работы сотрудников за счёт расширения числа специализированных агентов в нашей мультиагентной системе. Но давайте будем честны: мы начинали с решения совсем другой задачи.
Технические детали
Терминология на тот момент была ещё сырой и непроверенной, рынок open-source решений оставлял желать лучшего — мы выжимали максимум из того, что было доступно. Поэтому дальнейший рассказ будет полезен широкой аудитории: от тех, кто только начинает разбираться в теме, до руководителей отделов, которые хотят внедрить подобное решение у себя. Это вторая часть рассказа о том, как мы строили «Честного помощника» — мультиагентную систему на open-source моделях в «Честном знаке».
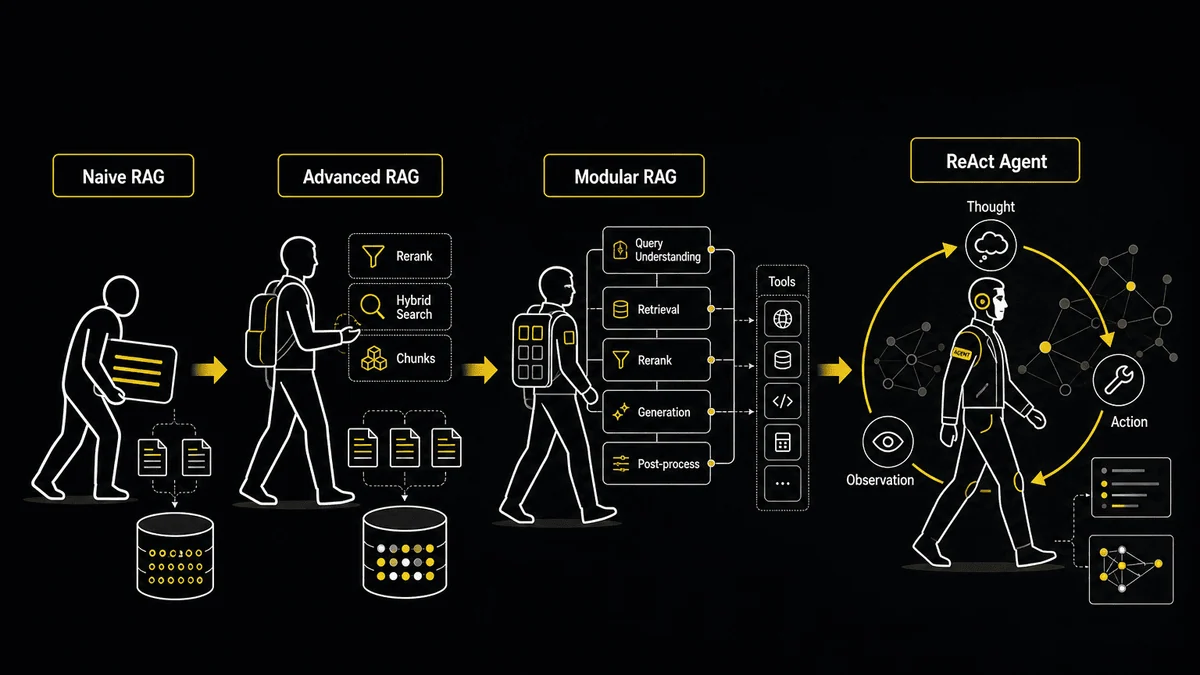
В первой части мы разобрали базовую терминологию и Naive RAG — подход, с которого начинает большинство команд. Если вы её пропустили, рекомендую начать оттуда: дальнейшее повествование опирается на понятия, которые мы там ввели. Advanced RAGПосле MVP стало понятно: проблема не в модели и не в векторной базе — проблема в том, что мы не умели ни нормально готовить документы к индексации, ни правильно обрабатывать запрос перед поиском, ни отфильтровывать лишнее после него.
Advanced RAG — это именно про это. Если Naive RAG — прямолинейный пайплайн «запрос → поиск → генерация», то Advanced RAG добавляет два дополнительных слоя:Pre-retrieval — всё, что происходит до поиска: переписывание запроса, расширение аббревиатур, построение маршрутов поиска, улучшение качества индексации. Post-retrieval — всё, что происходит после того, как чанки найдены: их перестановка, фильтрация, ранжирование, чтобы в LLM попадало только действительно релевантное.
Отраслевые последствия
Мы пошли по обоим направлениям одновременно, начав с того, что болело сильнее всего — с индексации. Оптимизация индексацииНа этапе MVP мы работали с готовым Confluence Loader и стандартным сплиттером. Это давало нам текст, но не давало качества.
В Advanced RAG мы переработали весь пайплайн обработки документов. Small-2-Big — изменили стратегию хранения и поиска чанков. Вместо того чтобы векторизовать и искать по крупным фрагментам, мы стали делать эмбеддинг на уровне отдельных предложений, а при нахождении релевантного предложения — расширять контекст вокруг него до более крупного фрагмента.
Это позволяет эмбеддеру точнее попадать в смысл запроса, а LLM получать достаточно контекста для ответа. Sliding Window — добавили перекрывающиеся чанки: каждый следующий фрагмент частично повторяет конец предыдущего.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.





