Лаборатория ИИ за 200 000 ₽: как мы собрали локальный ИИ-сервер на 2× Tesla V100
Dmitrii-Chashchin 2 часа назад Лаборатория ИИ за 200 000 ₽: как мы собрали локальный ИИ-сервер на 2× Tesla V100 Средний 27 мин 3.4K Управление продуктом * Искусственный интеллект DevOps * Управление проектами *...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
Значимый прорыв формирует отрасль ИИ: Dmitrii-Chashchin 2 часа назад Лаборатория ИИ за 200 000 ₽: как мы собрали локальный ИИ-сервер на 2× Tesla V100 Средний 27 мин 3. 4K Управление продуктом * Искусственный интеллект DevOps * Управление проектами * Управление продажами * Кейс Из песочницы О чём это и зачемПриятно наблюдать за тем, что сообщество людей, работающих с локальными ИИ, растет с каждым днем, но до сих пор я встречаю мнение, как сложно собрать нужное оборудование под свой сервер LLM. В интернете встречаются просто сумасшедшие суммы на сборки под ИИ, хотя все можно сделать гораздо проще, и своими руками.
Так и родилась идея сделать обзор на самую бюджетную серверную видеокарту V100 на 16/32 ГБ, приложив 100+ бенчмарков различных моделей, чтобы показать, как за малые средства можно приобрести целую лабораторию дома. Сразу оговоримся: «бюджетный» — это про соотношение цена/возможности, а не про «копейки». 200к за двухкарточный стенд по бытовым меркам — не дёшево.
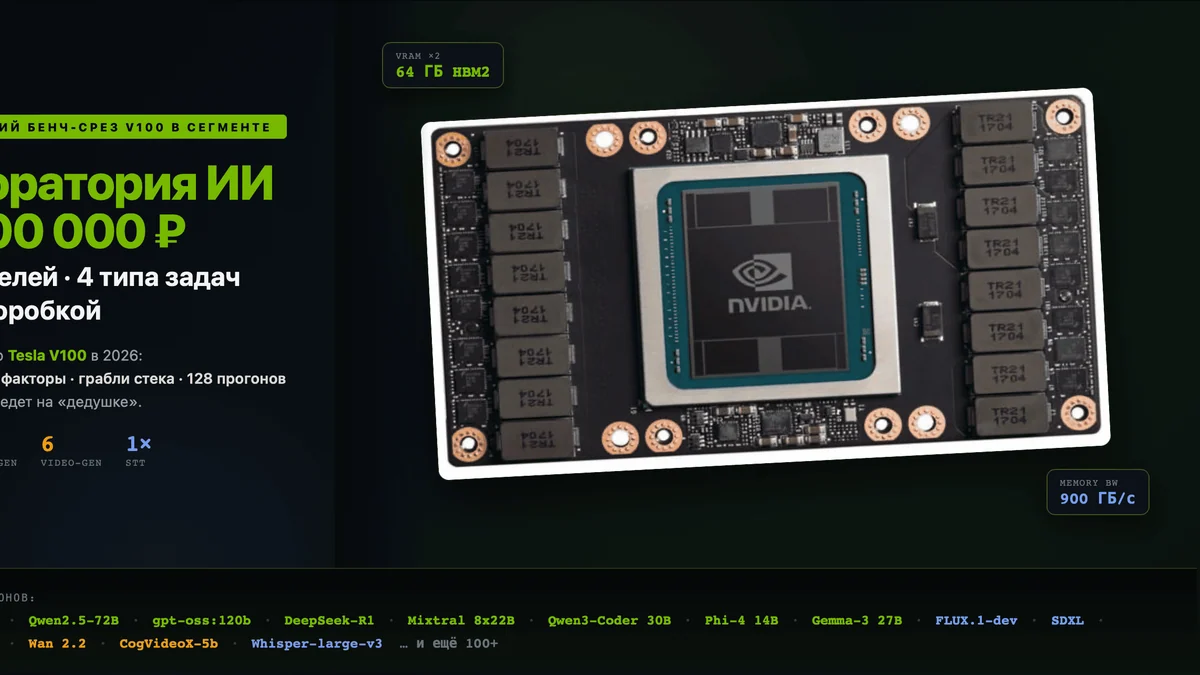
Технические детали
Но на этом железе крутятся модели вплоть до 70B AWQ через TP=2, а в этом ценовом сегменте ничего сопоставимого по VRAM мы на десктопе не нашли. 2× Tesla V100 32GB дают 64 ГБ VRAM суммарно — столько же, сколько три RTX 5080 16GB, и дешевле. Целевая аудитория — энтузиасты и небольшие команды до 50 человек, кому нужно крутить LLM локально по минимально возможной цене.
Для крупного продакшна V100 — компромисс, и в выводах честно разберём, где именно начинают вылезать его болячки. Цель — закрыть тему V100 одним материалом. По нашему опыту в русскоязычном поле полного разбора нет: где-то цены и нет стека, где-то стек и нет бенчей, где-то бенчи на одной модели.
В этой статье — и железо с ценами, и стек со всеми граблями, и реальные прогоны по четырём задачам: 108 LLM через Ollama, 14 image-gen через sd. cpp/Ollama, 6 video-gen через sd. cpp/diffusers, плюс STT-блок (Whisper-large-v3).
Отраслевые последствия
Карточки, JSON, скрипты и интерактивный дашборд — открытый репо pocketcoder-ch/v100-benchmarks-2026. Итого 128 прогонов в одной таблице. Что в статьеСтруктура такая:Что собираем и зачем (этот раздел).
Почему V100 — про рынок, форм-факторы (SXM2 vs SXM3 vs PCIe), Авито/АлиЭкспресс, что мы реально взяли. Железо: смета и почему именно так — i7, 2 карты, БП, RAM, корпус. Грабли Volta: vLLM-стек, что работает / что нет, SHM-wall и почему в массовом бенче мы в итоге на Ollama.
Как мы это всё тестировали — стенд, пайплайн STT+LLM, DP vs TP, путь A vs путь Б. 128 моделей в одной таблице — 108 LLM (топ-10 / рабочие лошадки 7–9B / большие 14–70B / «где упираемся в потолок»), 14 image-gen, 6 video-gen, STT (Whisper-large-v3). Когда NVLink реально нужен — практический вывод по 128 прогонам.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.




