AI-компаньон в проде на третьем месяце — 5 архитектурных решений и инфра-тюнинг
sm1ck 54 минуты назад AI-компаньон в проде на третьем месяце — 5 архитектурных решений и инфра-тюнинг Средний 25 мин 1.8K Искусственный интеллект Python * Машинное обучение * Кейс Из песочницы Каждый, кто пробовал...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
Значимый прорыв формирует отрасль ИИ: sm1ck 54 минуты назад AI-компаньон в проде на третьем месяце — 5 архитектурных решений и инфра-тюнинг Средний 25 мин 1. 8K Искусственный интеллект Python * Машинное обучение * Кейс Из песочницы Каждый, кто пробовал собрать AI-чат по типовой схеме — chat-completions API, OpenAI Memory, один эндпоинт Stable Diffusion — рано или поздно упирается в одни и те же стены. Бот забывает разговор через десять реплик.
Иногда сервер бодро отвечает HTTP 200, как будто всё в порядке, а внутри — пустая строка: ни ошибки, ни таймаута, модель просто отказалась говорить и сделала это молча. Один и тот же текстовый запрос рисует двух разных персонажей. А одеть нарисованного персонажа в конкретное платье из каталога не получается вообще.
Технические детали
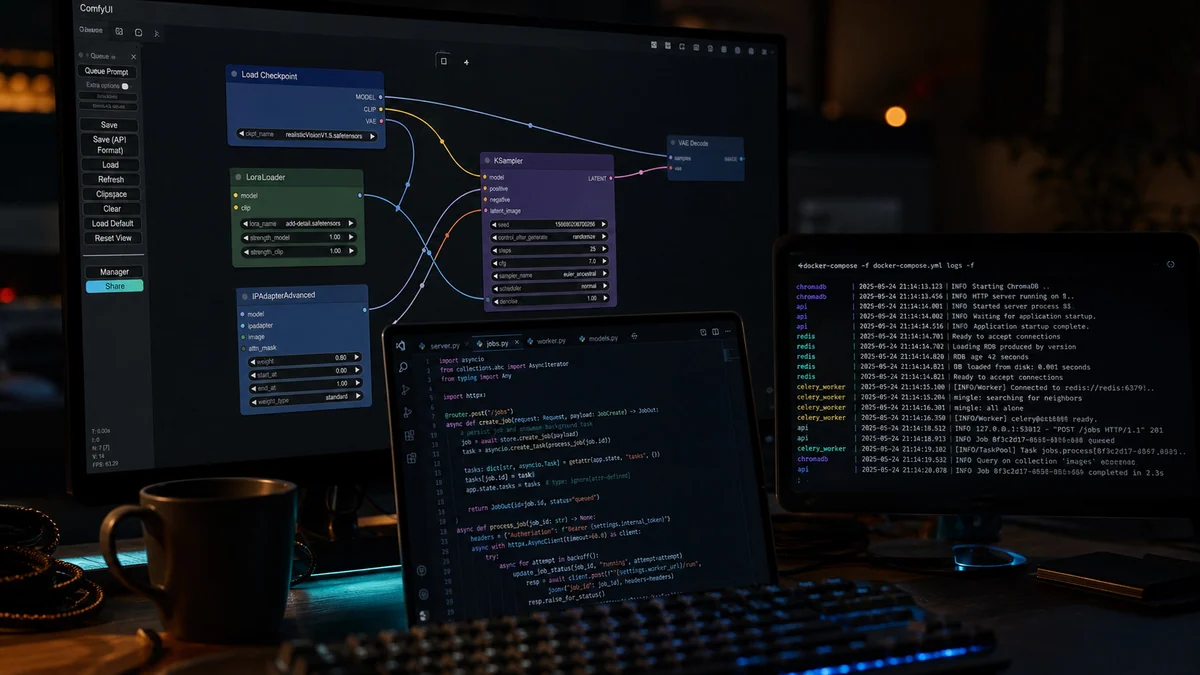
Я три месяца держу в проде AI-компаньона: один и тот же бэкенд обслуживает и Telegram-бот, и веб-приложение. Аудитория — сотни ежедневных пользователей, не сотни тысяч. Конверсия из бесплатного в платный тариф — однозначные проценты, как у любого продукта на ранней стадии.
Поэтому в статье не будет цифр про «миллион MAU», но будут цены за тысячу токенов, реальные доли попаданий в кеш, дневные потолки трат и до/после по тонкой настройке прода. Эта статья — четыре инженерных build-log поста, которые я выкладывал на dev. to (серия «Building HoneyChat»), сведённые в один связный материал на русском.
Плюс два раздела, которых в исходниках не было: про деньги (юнит-экономика на третьем месяце) и про операционный тюнинг, который сдвинул потолок DAU больше чем в два раза без переписывания архитектуры. ОглавлениеПамять: Redis + ChromaDBМаршрутизация LLM и кеш промптовВизуальная консистентность: LoRA и IP-AdapterЮнит-экономика на третьем месяцеПрод-тюнинг: что подкрутил в инфре на третьем месяцеЧто бы переделал, начав сейчасГде это работает в проде и источникиTL;DRПамять — Redis под свежий буфер реплик плюс ChromaDB под сжатые пересказы кусков диалога. Три чтения параллельно.
Отраслевые последствия
Превращать каждое отдельное сообщение в вектор — прямая дорога к индексу на миллионы документов с плохим поиском. Маршрутизация LLM — у пользователя в UI два темпа отношений (slow_burn и instant) плюс legacy-дефолт natural. Под каждый темп, под каждый тариф — своя модель.
Плюс цепочка резервных через разных провайдеров. Главная ловушка, на которой все спотыкаются: модель отвечает HTTP 200, а внутри пустая строка и причина «сработал фильтр контента» — не ошибка, не падение, просто тишина. Кеш промптов — на Gemini 3.
1 Flash Lite один маркер cache_control: ephemeral поверх системного промпта (это стартовые инструкции с описанием персонажа и правилами поведения) экономит 75% на закешированной части запроса. У меня этот один маркер закрывает четверть всего LLM-бюджета. Картинки — LoRA, небольшая надстройка над базовой моделью, которую вы дообучаете под каждого персонажа отдельно.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.




