Как мы укротили сложный процесс с помощью CQRS и стейт-машин
DioneyaOfCthulhu 26 минут назад Как мы укротили сложный процесс с помощью CQRS и стейт-машин Сложный 8 мин 783 Блог компании Timeweb Cloud Python * Open source * Программирование * IT-инфраструктура * Кейс Привет, Хабр!...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
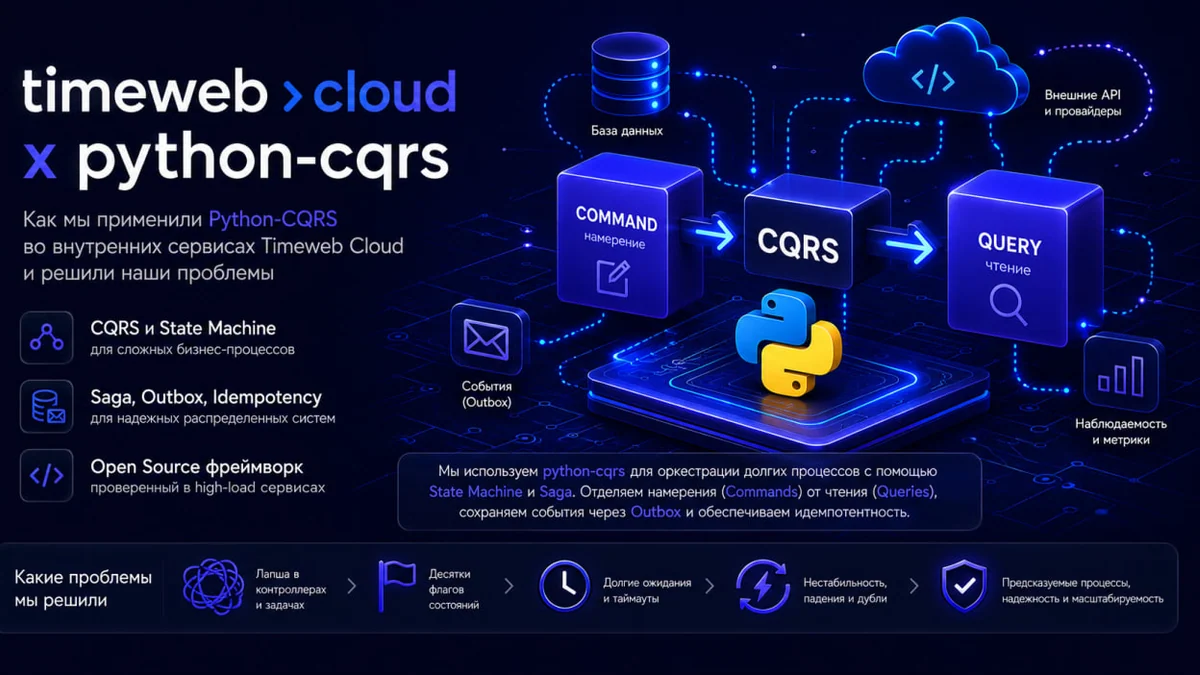
В сфере искусственного интеллекта произошло заметное событие. DioneyaOfCthulhu 26 минут назад Как мы укротили сложный процесс с помощью CQRS и стейт-машин Сложный 8 мин 783 Блог компании Timeweb Cloud Python * Open source * Программирование * IT-инфраструктура * Кейс Привет, Хабр! Меня зовут Никита, я являюсь разработчиком в направлении SSL инфраструктурной команды биллинга в Timeweb Cloud. Сегодня я хочу рассказать, как мы наводили порядок в коде одного из наших микросервисов, почему отказались от лапши в контроллерах, и главное — почему мы решили выложить наш внутренний архитектурный фреймворк в Open Source.
Если вы пишете на Python и хоть раз сталкивались с болью распределенных транзакций, отваливающихся внешних API и проблемой dual-write (двойной записи) — присаживайтесь поудобнее. Речь пойдет про наш open-source фреймворк python-cqrs (он же доступен на PyPI). Введение: Боль и проблемаВ нашей инфраструктуре есть бизнес-процессы, которые не сводятся к простому синхронному HTTP-запросу.
Технические детали
Отличный пример — автоматизированный выпуск SSL-сертификатов. Казалось бы, что сложного? Принял запрос от клиента, сходил по API к внешнему провайдеру, получил данные, отдал клиенту.
Но реальность сурова. Взаимодействие с внешними провайдерами — это распределенный, долгоживущий процесс (long-running process), который может занимать часы. Типичный флоу заказа выглядит примерно так:Подать заявку (сделать заказ через внешнее API).
Получить токены (challenges) для подтверждения прав. Установить эти токены на серверах. Обновление систем (например, DNS) может занимать от 15 минут до нескольких часов.
Отраслевые последствия
Инициировать проверку на стороне провайдера. Получить финальный результат и применить его. На любом из этих шагов что-то может пойти не так.
Внешний сервер ответит 500-кой, данные не успеют обновиться, процесс упадет и т. Раньше, в «старой парадигме», вся логика таких процессов часто лежала прямо в Celery-тасках или «толстых» сервисах. Мы писали бесконечные try/except, заводили отдельные таски на ожидание, плодили десятки флагов состояний в базе данных и писали скрипты-чистильщики, которые пытались восстановить зависшие заявки.
Со временем разобраться в этом графе переходов становилось невозможно, код был хрупким, а добавление интеграции с новым провайдером сертификатов превращалось в боль. К какому решению пришли? Мы поняли, что нам нужен строгий архитектурный подход.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.




