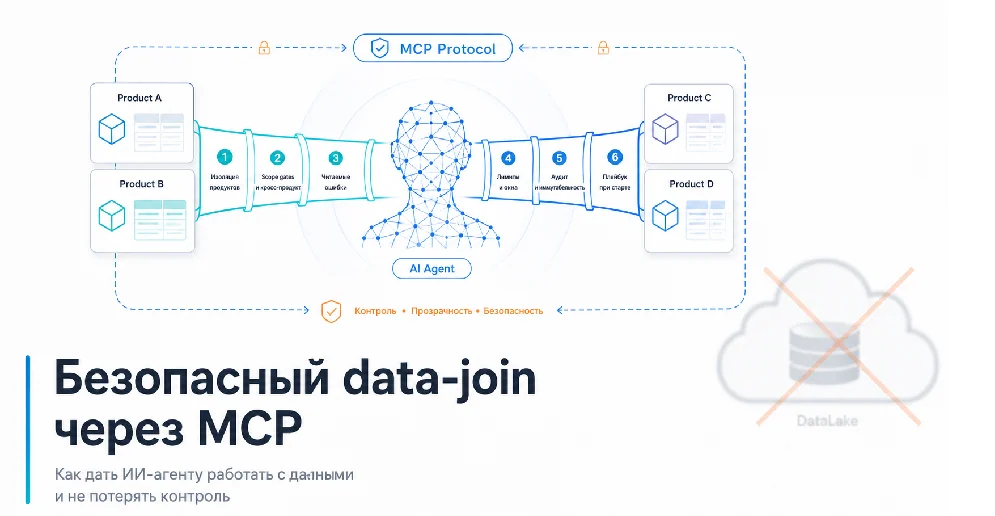
Как дать ИИ-агенту работать с данными и не потерять контроль: безопасный data-join через MCP, вместо создания DataLake
cyber_river 9 минут назад Как дать ИИ-агенту работать с данными и не потерять контроль: безопасный data-join через MCP, вместо создания DataLake Средний 9 мин 180 TypeScript * Data Engineering * Big Data * Кейс Это...
Anthropic — What company has the best second artificial intelligence model at the end of June?
Значимый прорыв формирует отрасль ИИ: cyber_river 9 минут назад Как дать ИИ-агенту работать с данными и не потерять контроль: безопасный data-join через MCP, вместо создания DataLake Средний 9 мин 180 TypeScript * Data Engineering * Big Data * Кейс Это продолжение новых безопасных паттернов по работе с MCP, которые я для себя придумал, которые я описал в статье:Как дать ИИ-агенту доступ к проду и не поседеть: безопасный production-дебаг через MCPВсем привет! Хотел поделится интересным паттерном взаимодействия, который удалось выстроить и он дов... comИнтересно будет услышать ваше мнение.
Теперь немного истории, проблема копилась в части того, что при развитии продукта постоянно появлялись запросы по аналитике, и все они упирались в решение, "А давайте сделаем DataLake". За больше чем 20 лет я очень много внедрял BI, OLAP, MOLAP и тд. У меня в начале 2000-х был какой-то фетиш на книги Тома Кайта по Ораклу и я вообще думал, что Оракл это лучшая база на свете.
Технические детали
Потом были увеличения Дейтом, Кимбалом, 3х уровневой моделью хранилища, 2х, Data Lake, Molap тд. Но щас чего-то немного надоело. Возникла простая мысль:"А можно ли налету объединять наборы данных на лету, без необходимости их куда-то перегружать, при этом преобразование будет выполнено в момент обращения к ним.
Такое точечный миникуб"ПроблемаКлассический запрос от аналитика звучит так:“Вот clients. Найди тех, у кого не было активности за 30 дней. ”Обычно это значит:ручной выбор product/окружения;ad-hoc SQL в продовой БД;копирование результатов в ноутбук (если нет DataLake, который надо строить);риск перепутать продукт или вытащить лишнее.
Если добавить в эту схему ИИ-агента и просто дать ему “универсальный тул”, риски умножаются:агент неявно уходит в чужой продукт;грузит слишком много данных “на всякий случай”;после ошибки циклически повторяет тот же запрос;результат невозможно нормально расследовать в аудите. Нужен был не “умный SQL”, а безопасный, типизированный, управляемый API для агента. Например:я хочу понять какие клиенты, у меня не заходили в продукт на этой неделе:- беру список клиентов например, выгружаю в CSV- беру сессии по user_id- пишу в курсор, подготовь список клиентов кто неделю не заходил в сервис и построить воронку по ретеншену.
Отраслевые последствия
так чтобы еще и данные не скомпрометировать. Так чтобы еще и перс. данные не грузить клиентов.
И так чтобы на сервере не осталось перс. И тут родилась идея, как это сделать. Идея: не SQL-песочница, а сценарные data-тулыЧасто руководя аналитиками и подразделениями, я видел одну и туже проблему.
Люди просто смотрят таблички, без какого-то понятного сценария использования данных. Часто руководители просто просили таблички ради табличек, это было удручающее. Когда ты спрашивал, "А зачем ты это посчитал", в ответ обычно было какое-то мычания.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.