Автоматический отбор few_shot примеров для обучения модели
yrgreen 20 минут назад Автоматический отбор few_shot примеров для обучения модели Средний 9 мин 721 Data Engineering * IT-компании Python * Алгоритмы * Кейс Из песочницы 1. ВведениеНормализация справочников НСИ -...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
Вот важная новость с фронта ИИ: yrgreen 20 минут назад Автоматический отбор few_shot примеров для обучения модели Средний 9 мин 721 Data Engineering * IT-компании Python * Алгоритмы * Кейс Из песочницы 1. ВведениеНормализация справочников НСИ - головная боль аналитиков: в базе десятки тысяч записей, и каждая будто создана по своим правилам. И это еще не все трудности: в базе полно дублей, форматы данных пляшут, в полях то лишние символы, то транслитерация, то опечатки от ручного ввода.
Мы не раз сталкивались с этим в своих проектах. Решений хватает, но мы остановили выбор на LLM. Модель хорошо справляется с разбором неструктурированных строк на атрибуты, если правильно её настроить.
Технические детали
Однако на практике мы столкнулись с тем, что успех LLM-нормализации на 90% определяется качеством few-shot примеров. Чем набор примеров репрезентативнее, тем стабильнее результат. Но как найти те самые, хорошие примеры в огромной массе разнородных записей?
Вручную, особенно не имея достаточной экспертизы, проводить глубокий анализ трудоемко и неэффективно. Поэтому мы решили пойти другим путём - автоматизировать подбор. В этой статье мы разберем два подхода к автоматизации процесса подбора примеров для обучения, проверим их на реальных данных и выясним, какой из них и в каких условиях работает лучше.
Посмотрим, что нам покажут «автоматические эксперты». Постановка задачи и метод оценкиНачнем с постановки задачи. Есть справочник МТР, в котором находятся различные строки с товарными позициями, например «Кабель ВВГнг 3х2.
Отраслевые последствия
мм, серая изоляция, 100м». Нужно разложить их по атрибутам:Атрибут ЗначениеВид продукции Кабель Марка ВВГнгСечение3x2,5 кв. ммЦвет изоляции серыйДлина100мЧтобы LLM справилась с этим хорошо, нужно показать ей правильные примеры.
Случайные 10 строк из базы здесь не подойдут. Если в выборке 800 кабелей ВВГ из 1000, случайный отбор с высокой вероятностью даст 7-8 однотипных примеров, и модель просто не увидит остальные паттерны. Нужны такие примеры, которые одновременно похожи на то, что будем выгружать из систем, и которые покрывают весь спектр данных.
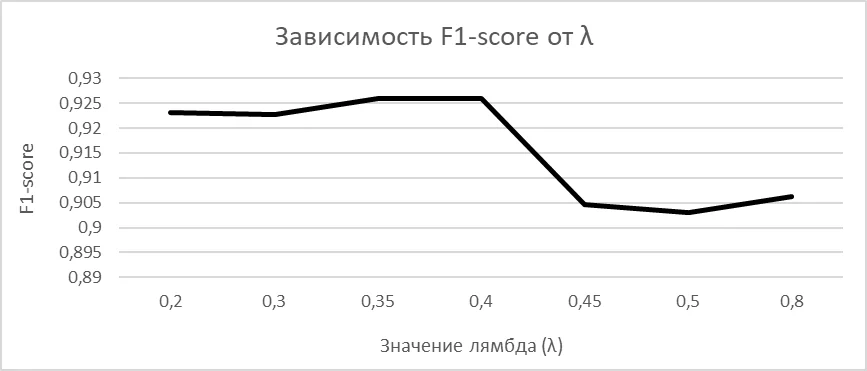
С этим нам может помочь метод MMR (Maximum Marginal Relevance). На каждом шаге из оставшихся кандидатов выбирается тот, кто близок к центру выборки и при этом непохож на уже отобранные примеры:Где:Sim - косинусное сходство между векторами;λ - параметр баланса;претендент - любой ещё не отобранный пример из выборки;среднее по выборке - усреднённый вектор всех кандидатов, условный центр тяжести входных данных;отобранные - примеры, выбранные на предыдущих шагах. На наших данных оптимальным оказалось λ = 0.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.




