Аналог Plaud на iPhone: эксперименты с локальной транскрибацией ASR на iOS
leviva23 11 минут назад Аналог Plaud на iPhone: эксперименты с локальной транскрибацией ASR на iOS Средний 12 мин 272 Swift * iOS * Разработка мобильных приложений * Xcode * Кейс ИдеяМы делаем приложение Memo: есть куча...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
Значимый прорыв формирует отрасль ИИ: leviva23 11 минут назад Аналог Plaud на iPhone: эксперименты с локальной транскрибацией ASR на iOS Средний 12 мин 272 Swift * iOS * Разработка мобильных приложений * Xcode * Кейс ИдеяМы делаем приложение Memo: есть куча гаджетов и сервисов вроде Plaud — это когда ты платишь за отдельную «умную» коробочку-диктофон, которая записывает встречу и сама делает из неё протокол. Зачем покупать отдельную железку, если в кармане уже есть iPhone? Давайте соберём такой же «умный протоколщик» прямо на телефоне.
записать встречу (с телефона или с Apple Watch);распознать речь — превратить звук в текст (это задача распознавания, ASR);обработать текст — сделать из расшифровки нормальный протокол: о чём договорились, какие задачи, кому что делать, плюс можно собрать письмо по итогам или свой запрос (задача на LLM);сгруппировать встречи — свести несколько встреч в один блок и выгрузить в свой ChatGPT или Claude, чтобы получить как бы личную цифровую память по своим рабочим разговорам. В этой статье расскажу про две самые интересные (и болезненные) части: распознавание речи и обработку. Будет две части:Как мы работаем с чужими моделями (OpenAI, OpenRouter) и почему пока не переехали на Яндекс и Сбер.
Технические детали
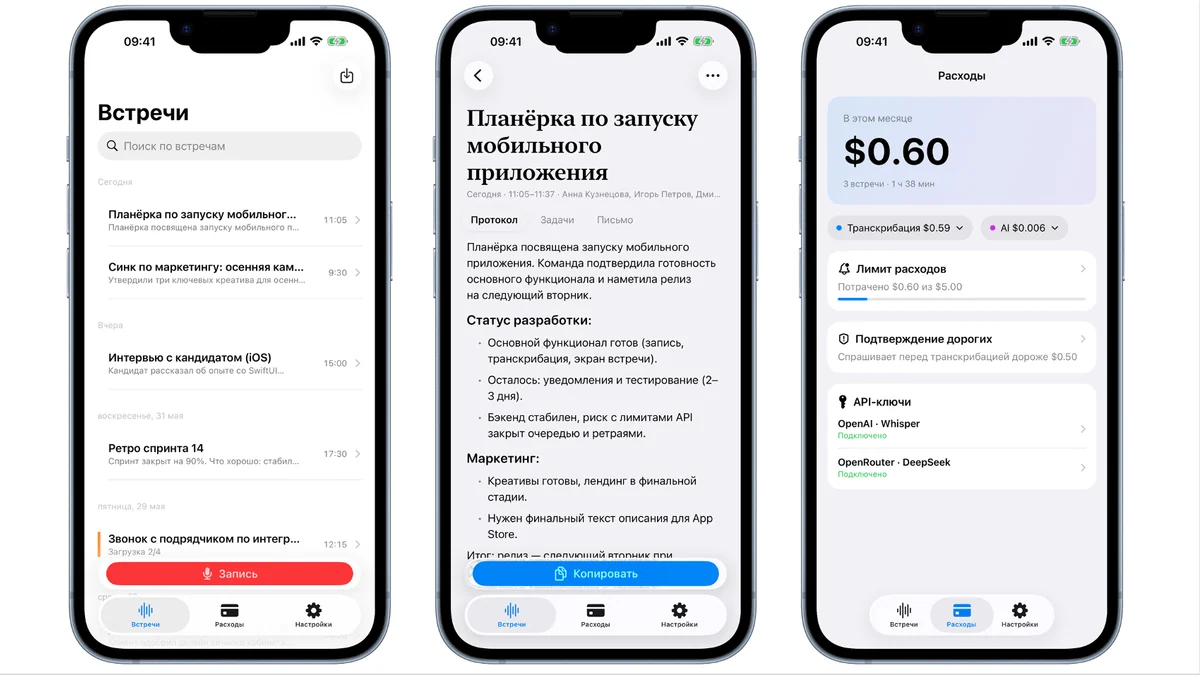
Наш заход на распознавание прямо на телефоне — где всё оказалось не так, как написано в документации. Если совсем коротко: нажал «Запись» → приложение записало встречу → звук ушёл на распознавание → на выходе ты получаешь текст расшифровки и готовый протокол. Плюс можно накидать письмо по итогам или свой запрос.
Всё крутится на iOS 26, писали на SwiftUI. Есть ещё версия для Apple Watch, чтобы можно было начать запись с руки. Важная деталь про архитектуру: у нас нет своего бэкенда.
Приложение пишет звук на телефоне и отправляет его напрямую выбранному провайдеру (OpenAI, OpenRouter и т. ), ответ так же напрямую возвращается в приложение. Перехватить или залогировать запись на нашей стороне нельзя, потому что нашей стороны в этом маршруте нет.
Отраслевые последствия
Отсюда же требование: нужны свои ключи от провайдеров — мы не зашивали внутрь ни ключей, ни оплаты. Так проще с ревью Apple и не приходится возиться с перепродажей токенов: свои ключи, свои расходы, мы к деньгам не прикасаемся. Главная техническая головная боль тут одна: звук надо надёжно превратить в текст, а потом текст — в нормальный документ.
Вокруг этого вся история ниже. Работа с внешними моделямиЛогика работыРаспознавание речи (звук → текст) — OpenAI. По умолчанию модель gpt-4o-mini-transcribe: она стоит 0.
003$ за минуту записи (это ~0. 18$ за час) — ровно вдвое дешевле старого whisper-1, у которого 0. Whisper-1 оставили для случаев, где нужны точные таймкоды по фразам (чтобы тапнуть по строке и перемотать аудио на это место).
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.