Retrieval в 2026: как RAG переехал с энкодеров на LLM (и что с этим делать в своём проекте)
photonchikk 18 минут назад Retrieval в 2026: как RAG переехал с энкодеров на LLM (и что с этим делать в своём проекте) Средний 8 мин 581 Natural Language Processing * Open source * Искусственный интеллект Машинное...
Anthropic — What company has the best second artificial intelligence model at the end of June?
Значимый прорыв формирует отрасль ИИ: photonchikk 18 минут назад Retrieval в 2026: как RAG переехал с энкодеров на LLM (и что с этим делать в своём проекте) Средний 8 мин 581 Natural Language Processing * Open source * Искусственный интеллект Машинное обучение * Поисковые технологии * Обзор Из песочницы Если вы строили RAG в 2023, ваш стек выглядел плюс-минус одинаково. BERT-семейство (BGE, e5) для семантики, BM25 для буквальных совпадений, cross-encoder для реранкинга, какой-нибудь Qdrant сверху. Этим жили два года, и многие до сих пор так живут.
Но если посмотреть, кто реально гоняется в продакшене у команд, которые ушли вперёд, ландшафт другой. Энкодеров там почти нет. Эмбеддит файнтюненная LLM.
Технические детали
Инференс на SGLang, а не на ONNX. И вся обвязка перестроилась под это. Эта статья про то, что поменялось и как переиспользовать этот стек у себя.
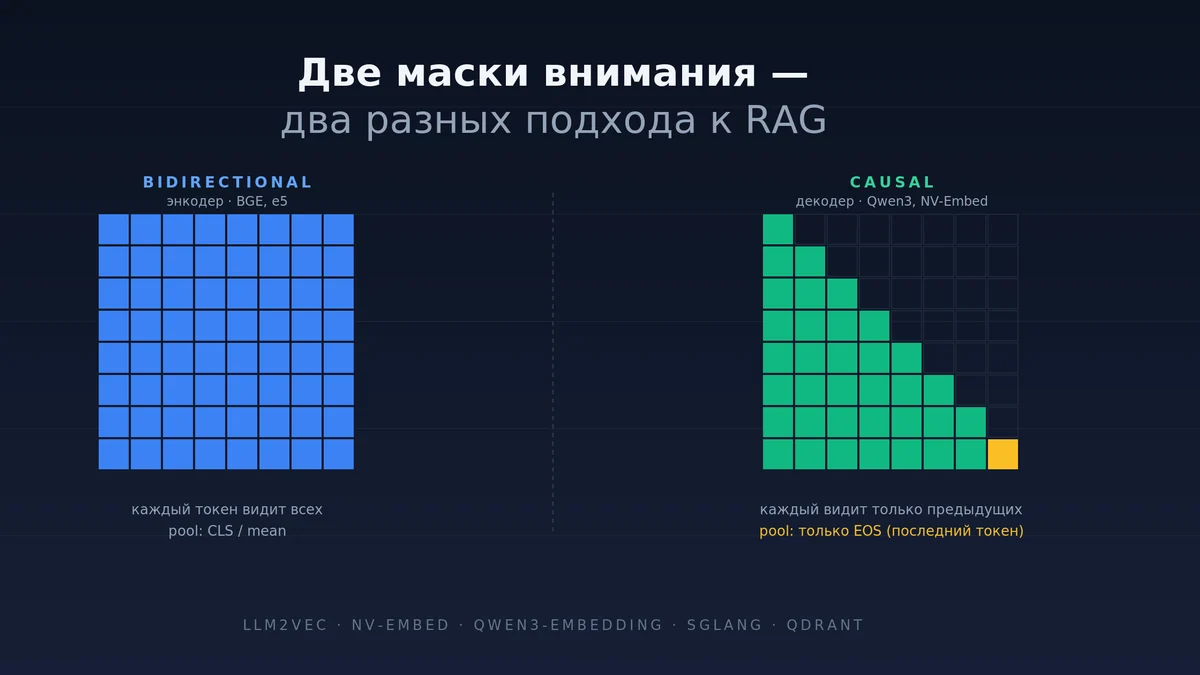
Особенно если вы работаете в узком домене, где готовых датасетов нет. Что было: классический стек и его потолокДефолтный retrieval делал три вещи. Энкодер берёт текст, прогоняет через bidirectional трансформер, собирает информацию в один вектор — через токен или усреднение.
Этот вектор кладётся в векторную базу, по нему ищется ближайший сосед по косинусу. Параллельно работает BM25 для точных совпадений по словам — нужен, потому что эмбеддер плохо ищет коды, артикулы, номера законов. Сверху cross-encoder переранжирует топ-K и отдаёт пользователю.
Отраслевые последствия
Где этот стек упёрся:Узкие домены он не вытягивает. Если BGE на претрейне не видел юридический корпус, вы не дотянете его до приличного качества простым bge-large вместо bge-base. Длинный контекст — до свидания.
Большинство энкодеров живёт в районе 512 токенов, чуть больше у Jina и Nomic. Поэтому появился весь зоопарк chunking-стратегий в LangChain. Инструкции под задачу нельзя задать на лету.
Хотите retrieval — учите модель под retrieval, под классификацию — учите отдельно. ONNX Runtime поддерживается номинально, flash attention туда так и не завезли, prefix caching нет. Сообщество перешло на vLLM и SGLang под декодеры, а энкодерам ничего не досталось.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.





