Опасности первичных ключей UUID в SQLite и оптимизация данных
PatientZero 11 минут назад Опасности первичных ключей UUID в SQLite и оптимизация данных 6 мин 263 Базы данных * SQLite * Серверная оптимизация * Перевод Автор оригинала: Anders Murphy В базах данных в качестве...
Anthropic — What company has the best second artificial intelligence model at the end of June?
В сфере искусственного интеллекта произошло заметное событие. PatientZero 11 минут назад Опасности первичных ключей UUID в SQLite и оптимизация данных 6 мин 263 Базы данных * SQLite * Серверная оптимизация * Перевод Автор оригинала: Anders Murphy В базах данных в качестве первичных ключей часто используют случайные UUID. Один из известных недостатков случайных UUID заключается в том, что их неупорядоченность (UUID4) может вызывать большое количество дополнительных обращений к страницам кластеризованных индексов (clustered index), потому что строки вставляются в случайные места B-дерева, и его приходится постоянно перебалансировать. В этой статье я попытаюсь помочь вам выработать более интуитивное понимание того, как влияют на производительность все эти дополнительные операции со страницами.
Хотя статья посвящена конкретно SQLite, проблема случайных UUID касается и других баз данных, использующих кластеризованные индексы. Что такое кластеризованные индексы? Кластеризованные индексы определяют физический порядок хранения строк в таблице.
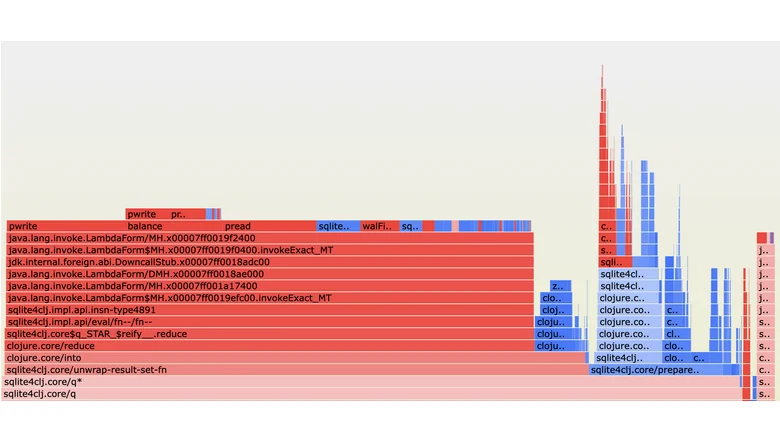
Технические детали
Из-за этого:Для каждой таблицы может существовать только один кластеризованный индекс (строки можно физически отсортировать только одним способом). Кластеризованный индекс — это таблица. Некластеризованный индекс хранит только индексированные столбцы плюс указатель на сами данные строк, которые находятся в другом месте.
RowidУ каждой обычной таблицы SQLite есть внутренний 64-битный целочисленный первичный ключ, называющийся rowid. Данные таблицы хранятся в структуре B-дерева, содержащей по одному элементу на каждую строку таблицы и использующей в качестве ключа значение rowid. По сути, это кластеризованный индекс SQLite.
Порядок физического хранения строк соответствует порядку rowid. Без rowidSQLite также поддерживает таблицы WITHOUT ROWID. У этих таблиц нет внутреннего rowid.
Отраслевые последствия
Вместо него кластеризованным индексом становится объявляемый вами первичный ключ. Зачем использовать таблицы без rowid? Просто потому что благодаря этому не нужно хранить индекс rowid и индекс первичных ключей, что снижает объём записи.
Но при этом для получения самих данных всё равно требуется дополнительный поиск даже в случае, когда в качестве rowid используется первичный ключ (если только индекс не покрывающий). Примечание: в SQLite таблицы с rowid реализованы в виде B+-деревьев, в которых всё содержимое хранится в листьях, а таблицы WITHOUT ROWID реализованы в виде обычных B-деревьев, где содержимое хранится и в листьях, и в промежуточных узлах. Отправная точкаДавайте зададим отправную точку производительности с обычным целочисленным первичным ключом rowid.
Вставим 10 миллионов строк группами по 1 миллиону. (d/q writer ) (dotimes (time (d/with-write-tx (dotimes (d/q db )))))Результаты:Общее количество строкВремя в миллисекундах10000008382000000762300000081940000007135000000721600000075770000006928000000702900000069610000000715Примерно миллион вставок в секунду.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.





