Одна и та же модель выдала 28% и 76% на одном бенчмарке. Разница — в способе подачи вопросов
StefanBidzhamov 12 минут назад Одна и та же модель выдала 28% и 76% на одном бенчмарке. Разница — в способе подачи вопросов Сложный 5 мин 325 Искусственный интеллект Аналитика Из песочницы Я собирал бенчмарк для...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
В сфере искусственного интеллекта произошло заметное событие. StefanBidzhamov 12 минут назад Одна и та же модель выдала 28% и 76% на одном бенчмарке. Разница — в способе подачи вопросов Сложный 5 мин 325 Искусственный интеллект Аналитика Из песочницы Я собирал бенчмарк для русскоязычных LLM на корпоративных документах: политики, приказы, счета, согласования. Хотел проверить, умеет ли модель найти нужный документ среди похожих, сослаться на конкретную строку и не сломаться, когда в одном из документов меняешь одну дату.
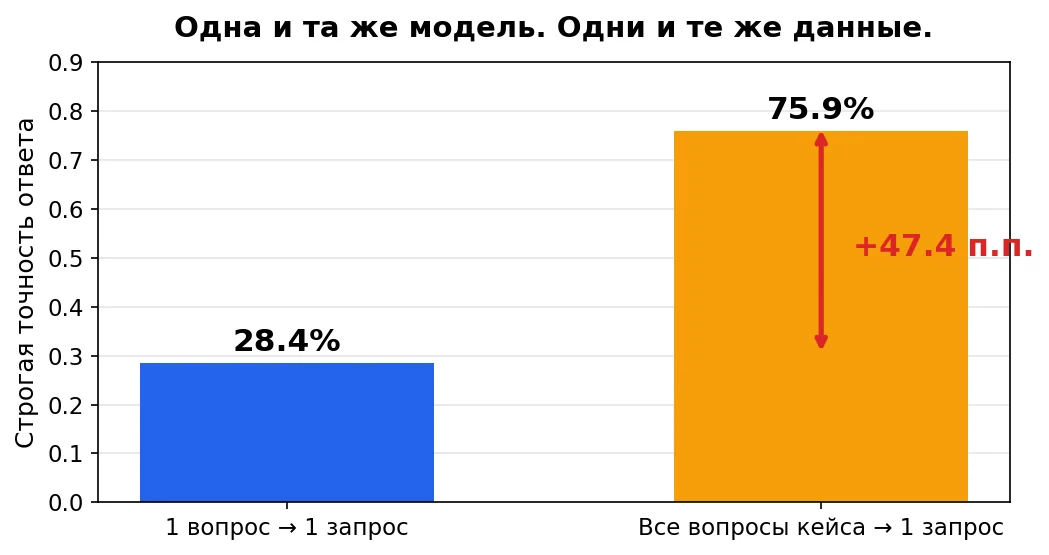
В этом эксперименте результат оказался сильно зависим от того, как были организованы запросы к модели. Одна и та же модель, одни и те же данные, разница 47. 4 пунктаЭтот эксперимент показывает, что итоговая точность LLM зависит от всего протокола взаимодействия: структуры промпта, доступного контекста, схемы ответа и правил обработки ошибок.
Технические детали
Одна и та же модель на одних и тех же данных дала 28. 9% при разной подаче вопросов. Для исследований это означает, что результаты бенчмарков и лидербордов нужно сравнивать только при точно описанном протоколе, а в прикладных системах качество можно заметно повысить за счёт организации запросов и structured output.
В эксперименте зафиксированы одна модель — qwen3. 5:4b, один набор из 1 160 задач и одинаковые эталонные ответы. Менялся только способ подачи вопросов.
4 пункта сохранился во всех 10 000 бутстрэп-репликах и оказался положительным в каждом из 30 кейсов. Практический смысл: число, которое попадает в README как «accuracy», заметно зависит от того, как упакован промпт. Ниже разберу, что именно ломается, и покажу баг, который объясняет значительную часть разрыва.
Отраслевые последствия
Устройство кейсаПокажу на конкретном примере, иначе дальше будет абстрактно. Кейс с командировкой. Общая политика задаёт лимит на гостиницу 9 000 ₽ за ночь.
Сверху лежит временный приказ, поднимающий лимит до 12 000 ₽. Есть счёт из гостиницы на четыре ночи. Чтобы посчитать сумму к возмещению, модель должна определить, какой документ главнее, проверить срок действия приказа и сложить.
В варианте B я меняю в приказе одну строку — дату окончания — так, что приказ перестаёт действовать к четвёртой ночи. Максимальная сумма должна измениться с 48 000 ₽ на 45 000 ₽. При этом ответ на вопрос про базовую политику («какой лимит без приказов?
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.