Свой инструмент для бенчмаркинга ИИ-агентов: архитектура, надёжность и интеграция с Airflow
Всем привет! Мы создаём GraphRAG-систему и нам постоянно приходится тестировать новые гипотезы: менять подходы к поиску по графу, обработку контекста, внешние интеграции и вспомогательные компоненты. Почти каждая такая...
Anthropic — What company has the best second artificial intelligence model at the end of June?
В сфере искусственного интеллекта произошло заметное событие. Мы создаём GraphRAG-систему и нам постоянно приходится тестировать новые гипотезы: менять подходы к поиску по графу, обработку контекста, внешние интеграции и вспомогательные компоненты. Почти каждая такая гипотеза требует правок в коде или конфигурирования агента, а значит, быстро возникает несколько параллельных вариантов реализации, которые хочется сравнивать между собой.
При этом тестирование одной версии не должно блокировать тестирование другой. Разработчики должны иметь возможность одновременно прогонять бенчмарки для разных веток, реализаций и конфигураций, а затем выбирать наиболее удачные изменения и интегрировать их в основную версию агента, которая уже проходит путь до эксплуатации.
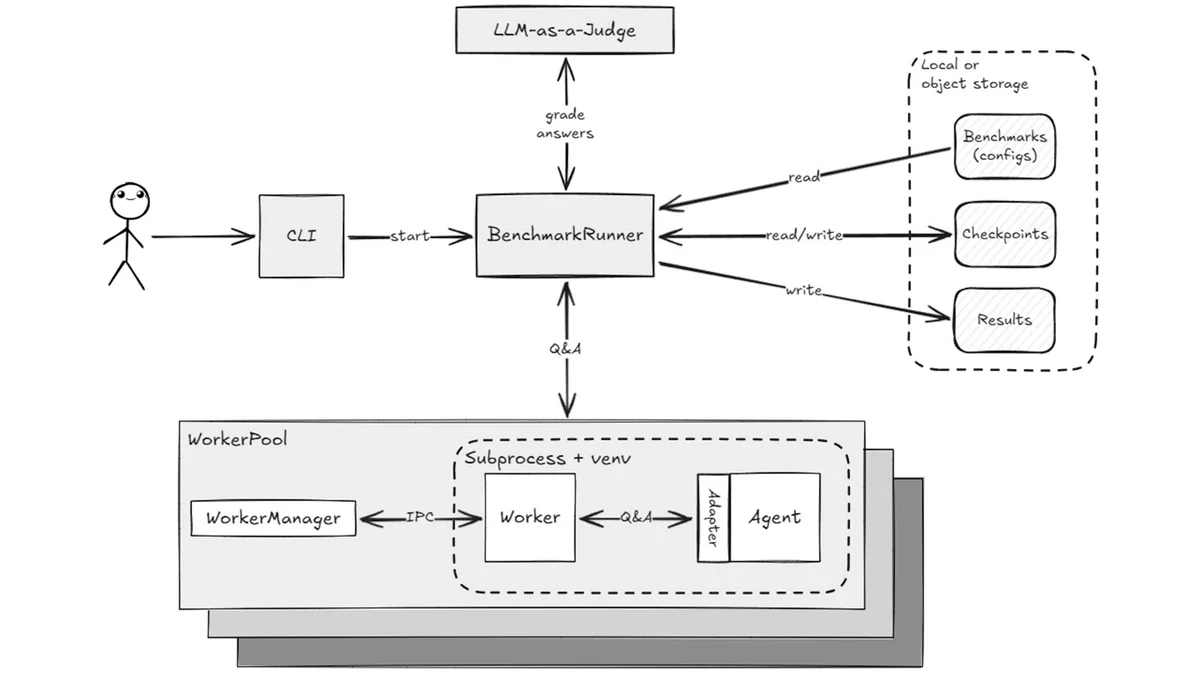
Технические детали
Другая проблема: агент — это не просто промпт к LLM, а комплексная кодовая база со своим окружением, множеством зависимостей и точек отказа. Тестирование его встраиванием в ноутбуки и кастомные скрипты может аукнуться неприятными побочными эффектами и необходимостью постоянно их дорабатывать под изменения в агенте или добавление новых агентов.
В результате задача «оценить качество агента» превращается не только в задачу про метрики, но и в задачу про инженерную надёжность: как воспроизводимо запускать агент, как не зависеть от конкретного агента или его версии, как не терять промежуточные результаты прогонов, как хранить артефакты и сравнивать результаты между версиями.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.





