Как мы ушли от ETL к CDC: выбираем архитектуру real-time аналитики на PostgreSQL, Kafka и ClickHouse. Часть 1
wakeupdeadpunk 11 минут назад Как мы ушли от ETL к CDC: выбираем архитектуру real-time аналитики на PostgreSQL, Kafka и ClickHouse. Часть 1 Средний 6 мин 276 PostgreSQL * DevOps * Хранение данных * Ретроспектива Из...
Anthropic — What company has the best second artificial intelligence model at the end of June?
Значимый прорыв формирует отрасль ИИ: wakeupdeadpunk 11 минут назад Как мы ушли от ETL к CDC: выбираем архитектуру real-time аналитики на PostgreSQL, Kafka и ClickHouse. Часть 1 Средний 6 мин 276 PostgreSQL * DevOps * Хранение данных * Ретроспектива Из песочницы Все началось с просьбы сделать отчеты в реальном времени. На первый взгляд задача выглядела простой, но довольно быстро выяснилось, что существующая архитектура для этого не подходит.
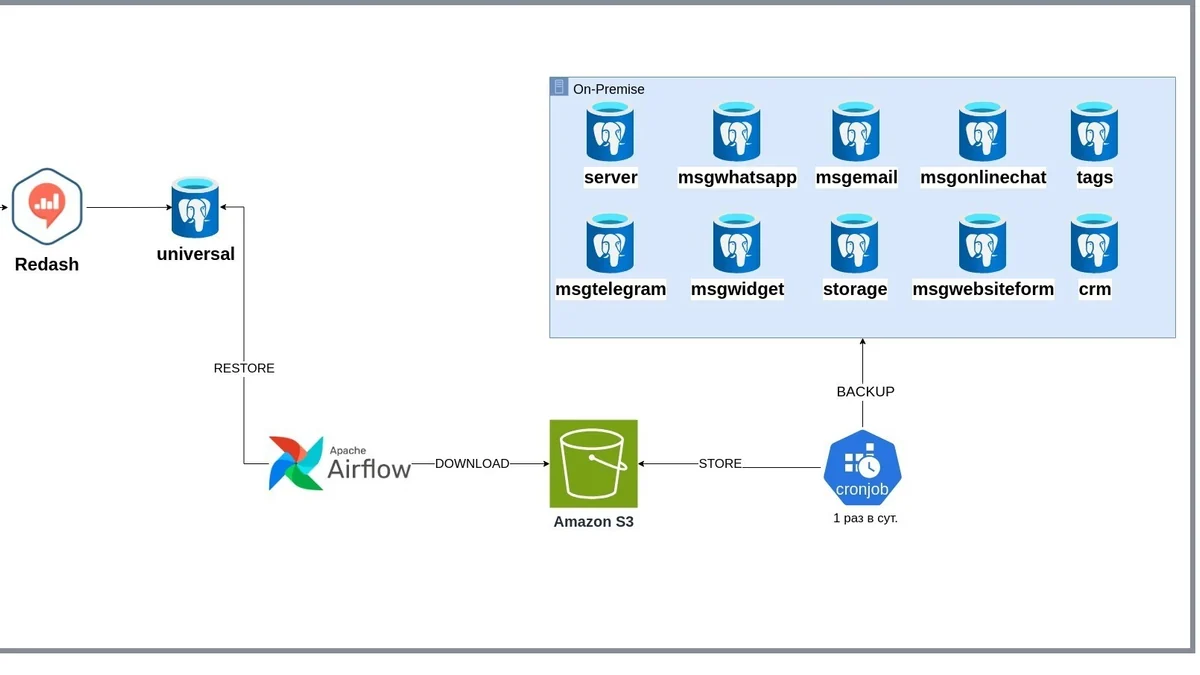
Проект был разбит на множество микросервисов, каждый из которых хранил данные в собственной PostgreSQL-базе. Чтобы строить сквозные отчеты, информацию нужно было где-то объединять. На тот момент аналитика уже работала через ETL: раз в сутки Airflow восстанавливал общую PostgreSQL из ежедневных бекапов, а Redash выполнял запросы уже к ней.
Технические детали
Решение было надежным и не требовало нагрузки на production, но для real-time оно не годилось — в лучшем случае отчеты показывали состояние системы на начало дня. Какую проблему нужно было решитьСуществующая схема была построена на классическом пакетном ETL. Раз в сутки Airflow скачивал резервные копии всех PostgreSQL-баз из S3, восстанавливал их и последовательно обновлял единую базу, к которой обращался Redash.
Пока объем данных был небольшим, такой подход не доставлял особых проблем. Но со временем начали проявляться его ограничения. Во-первых, все отчеты всегда отставали минимум на сутки.
Если утром в системе происходили изменения, увидеть их можно было только после следующего запуска ETL. Для финансовых показателей и операционной аналитики такой задержки было уже слишком много. Во-вторых, сам процесс синхронизации оказался достаточно тяжелым.
Отраслевые последствия
Во время восстановления нескольких дампов одновременно заметно возрастала нагрузка на дисковую подсистему, а передача резервных копий занимала существенную часть пропускной способности сети. И наконец, мы теряли историю изменений. Если одна и та же запись в течение дня несколько раз обновлялась, в аналитическую базу попадало только ее последнее состояние на момент создания резервной копии.
Все промежуточные изменения просто исчезали, а вместе с ними и возможность анализировать последовательность событий. В какой-то момент стало понятно, что увеличивать частоту ETL бессмысленно. Хотелось получить не просто более свежие данные, а механизм, который будет передавать изменения практически сразу после их появления и при этом не создавать дополнительную нагрузку на рабочие базы.
Какие варианты рассматривалиПрежде чем собирать отдельный контур аналитики, хотелось понять, можно ли обойтись более простыми решениями. Некоторые варианты отпали практически сразу, некоторые даже удалось проверить на тестовом стенде. Прямые запросы к рабочим PostgreSQLПервая идея выглядела максимально простой: подключить Redash напрямую к базам микросервисов и строить отчеты без каких-либо промежуточных хранилищ.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.