Event Sourcing в платформе данных: миграция с JSON на Avro
NeilPerry 3 минуты назад Event Sourcing в платформе данных: миграция с JSON на Avro Простой 9 мин 13 Блог компании CDEK Big Data * Data Engineering * Java * Хранение данных * Кейс Иногда legacy живёт в компании годами...
Anthropic — What company has the best second artificial intelligence model at the end of June?
Вот важная новость с фронта ИИ: NeilPerry 3 минуты назад Event Sourcing в платформе данных: миграция с JSON на Avro Простой 9 мин 13 Блог компании CDEK Big Data * Data Engineering * Java * Хранение данных * Кейс Иногда legacy живёт в компании годами не потому, что он плох, а потому что «работает — не трогай». Но однажды появляется триггер, который заставляет переосмыслить подход. В нашем случае таким триггером стала миграция на Kafka 4.
Меня зовут Роман, я инженер данных в компании CDEK и занимаюсь разработкой платформы данных и внедрением self‑service инструментов. В этой статье расскажу, как мы обеспечиваем Event Sourcing подход в платформе больших данных, с какой болью столкнулись при переходе на Kafka 4. 0 и как решились отказаться от JSON‑формата.
Технические детали
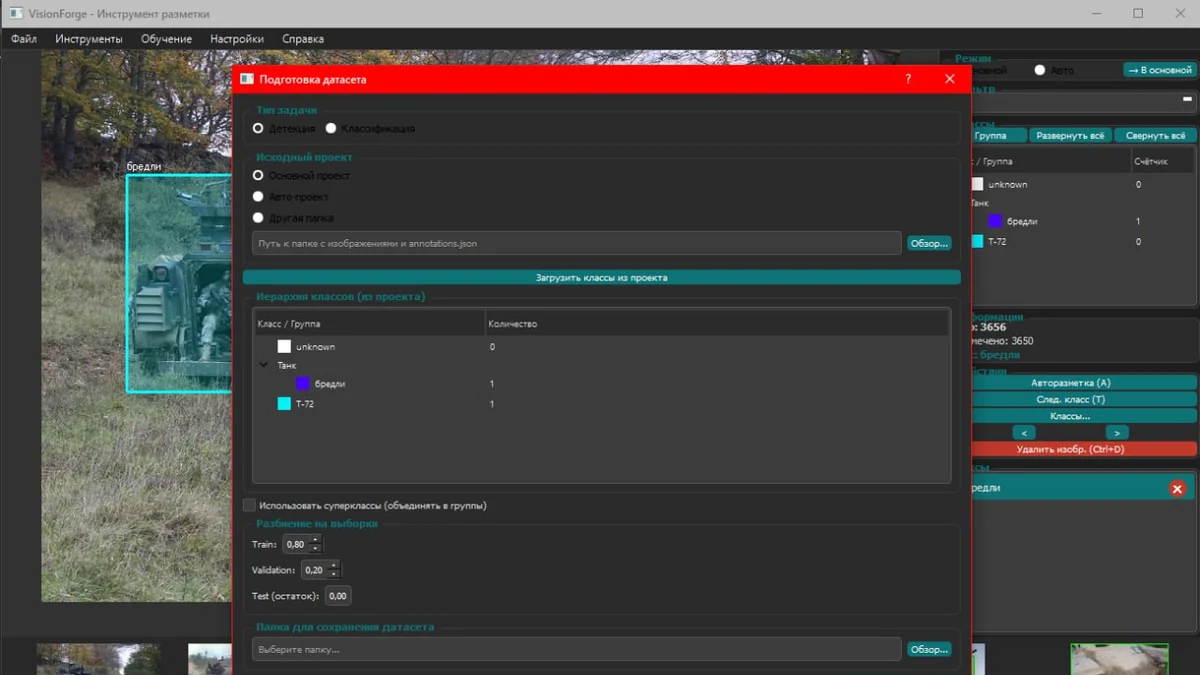
Подробно про эволюцию платформы данных в нашей компании можно прочесть в статье коллеги, но многое изменилось за последнее время. СодержаниеПотоковый ingest: как былоМинусы решения на Camel Kafka Connect и переезд в новый ЦОДЧем заменить Camel Kafka ConnectСвой ingest‑сервис на SpringСколько ресурсов затратилиНемного итоговПотоковый ingest: как былоНачнём с того: а откуда данные вообще попадают в BI. Фактически в CDEK основная ESB‑шина межмодульного взаимодействия происходит через кластер RabbitMQ.
BI получает ивенты и держит буфер в кафке. Какого‑то явного хайлоада здесь нет, мы слушаем порядка 200 обменников со средним MPS 2–5k сообщений. Далее данные пишем через Spark Structured Streaming (довольно нестандартно, да) в S3 для разных флоу.
Основной флоу, конечно, происходит через основное хранилище в виде Greenplum. На стороне хранилища ивенты либо пишутся все, либо сохраняется лишь последний стейт. Другой флоу для быстрой аналитики работает по такой же схеме, только данные пишутся в S3 как полноценные Iceberg‑таблицы.
Отраслевые последствия
Данные глубиной до месяца кэшируются из хранилища, и Spark раз в 15–60 минут строит витрины данных и доставляет их в ClickHouse для конечного пользователя. Ну и самый быстрый флоу — для плоских витрин, не требующих тяжелых JOIN‑операций: просто цепляемся к кафка‑топику через Kafka Engine кликхауса и сбрасываем данные раз в 1–5 минут. На первый взгляд, всё красиво и прекрасно, но дьявол кроется в деталях.
Минусы решения на Camel Kafka Connect и переезд в новый ЦОДПервая проблема заключалась в том, как забирались данные из RabbitMQ в кафку. Мы использовали открытый Camel Rabbitmq Source Connector, и здесь я остановлюсь подробнее. В декабре CDEK переезжал в новый ЦОД, и со стороны инфраструктуры было много обновлений.
Требовалось поднять версию кафки до 4. 0, но сюрприз‑сюрприз: мы не могли просто так взять и натянуть бинарные файлы Camel‑коннектора на свежую кафку.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.