IncidentRelay месяц спустя: от маршрутизации алертов к полноценному on-call workflow
Aidaho12 10 минут назад IncidentRelay месяц спустя: от маршрутизации алертов к полноценному on-call workflow Простой 4 мин 0 DevOps * Системное администрирование * Обзор Чуть больше месяца назад я впервые рассказал об...
Anthropic — What company has the best second artificial intelligence model at the end of June?
В сфере искусственного интеллекта произошло заметное событие. Aidaho12 10 минут назад IncidentRelay месяц спустя: от маршрутизации алертов к полноценному on-call workflow Простой 4 мин 0 DevOps * Системное администрирование * Обзор Чуть больше месяца назад я впервые рассказал об IncidentRelay, open-source и self-hosted системе для дежурств, маршрутизации алертов и эскалаций. В первой версии основная цепочка уже работала:Monitoring -> Route -> On-call -> Notification -> ACK / Resolve С тех пор проект добрался до v1. Цепочка стала длиннее, но пользоваться системой стало проще.
В отличие от некоторых корпоративных процессов, здесь усложнение действительно пошло на пользу. Не буду пересказывать весь changelog. Расскажу о нескольких изменениях, которые сильнее всего повлияли на продукт.
Технические детали
Дежурства стали похожи на настоящиеПростая ротация выглядит красиво: несколько инженеров по очереди дежурят сутки. Потом в неё приходят рабочие часы, выходные, отпуска, разные часовые пояса и человек, который только в пятницу вечером вспоминает, что завтра улетает. Поэтому в IncidentRelay появились многослойные ротации.
У каждого слоя могут быть свои:участники и приоритет;временные ограничения;часовой пояс;правила передачи смены. Поверх расписания работают временные замены. Календарь показывает уже итоговый результат после применения всех слоёв и overrides.
Расписание можно подключить к Google Calendar, Outlook, Apple Calendar и другим клиентам через ICS или read-only CalDAV. Пользователи также могут получать уведомления о предстоящих сменах. Появился On-call Health.
Отраслевые последствия
Он заранее ищет пустые слои, неактивных участников, разрывы в расписании, маршруты без получателя и проблемы с каналами уведомлений. Лучше увидеть красный индикатор днём, чем обнаружить ночью, что единственный дежурный существует только в базе данных. Двадцать алертов теперь могут стать одним инцидентомОдна проблема редко присылает одно аккуратное сообщение.
Обычно сначала жалуется база, потом API, затем очередь, а через минуту к обсуждению присоединяется всё, у чего есть доступ к Alertmanager. Теперь IncidentRelay умеет группировать связанные события по сервису, окружению, кластеру, имени алерта и другим labels. Для группы можно:задержать первое уведомление;настроить периодические обновления;выполнить ACK или Resolve сразу для всей группы;объединить несколько групп вручную;оставить комментарии и сохранить историю расследования.
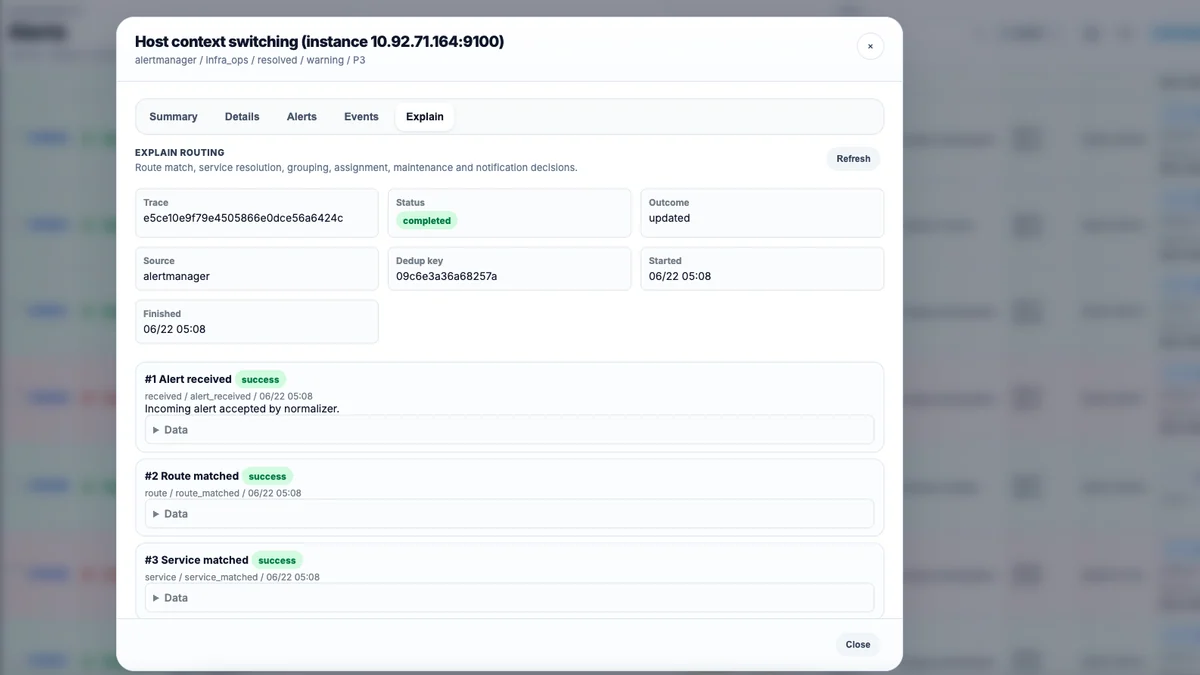
Исходные алерты при этом не теряются. Дежурный получает одну развивающуюся историю вместо серии сообщений с одинаковым смыслом и разной пунктуацией. Появилось понимание того, что именно сломалосьРаньше IncidentRelay хорошо отвечал на вопрос «кому отправить алерт», но почти ничего не знал о самом объекте аварии.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.