Разбираемся в ML без воды: от базы до Attention. Часть 12: Понижение размерности и PCA
В предыдущей части мы разобрали градиентный бустинг — финального босса в классическом обучении с учителем. Мы научились строить мощные ансамбли, которые выжимают максимум из табличных данных. Кажется, что на этом можно...
Anthropic — What company has the best second artificial intelligence model at the end of June?
В сфере искусственного интеллекта произошло заметное событие. В предыдущей части мы разобрали градиентный бустинг — финального босса в классическом обучении с учителем. Мы научились строить мощные ансамбли, которые выжимают максимум из табличных данных.
Кажется, что на этом можно ставить точку и прыгать в современный мир нейросетей и Deep Learning. Но до этого момента мы жили в идеальной теплице: у нас всегда была разметка (тот самый target, который нужно предсказать), а количество признаков в таблицах было разумным.
Технические детали
В реальности все иначе. Данных часто слишком много, в них куча шума, а правильных ответов никто не разметил.
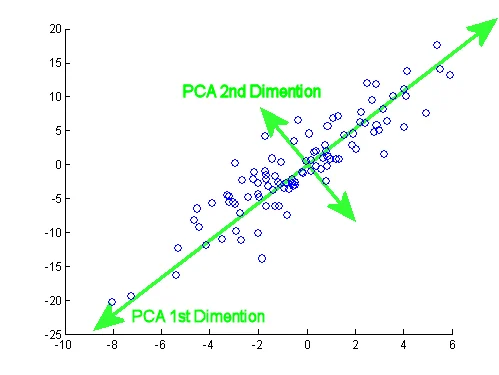
В этой части мы закроем очередную проблему в классическом ML — столкнемся лицом к лицу с проклятием размерности (curse of dimensionality). Поймем, как сжимать многомерные пространства, не теряя важный смысл, и как заставить машину самостоятельно группировать объекты в кластеры, вообще не имея готовых классов.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.





