Сжатие декодерных эмбеддеров: как ужать 8B до продакшена без потери recall
photonchikk 27 минут назад Сжатие декодерных эмбеддеров: как ужать 8B до продакшена без потери recall Средний 13 мин 1.2K Natural Language Processing * Open source * Искусственный интеллект Машинное обучение * Поисковые...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
Значимый прорыв формирует отрасль ИИ: photonchikk 27 минут назад Сжатие декодерных эмбеддеров: как ужать 8B до продакшена без потери recall Средний 13 мин 1. 2K Natural Language Processing * Open source * Искусственный интеллект Машинное обучение * Поисковые технологии * Туториал В прошлой статье мы разбирали, почему retrieval в 2026 переехал с энкодеров на декодерные LLM: Qwen3-Embedding, NV-Embed, E5-Mistral эмбеддят лучше BGE, держат 32k контекста и понимают инструкции в промпте. Декодерный эмбеддер 7–8B действительно дает качество.
Но за это качество вы платите трижды: память (8B в fp16 - не только веса модели, но и жирные векторы в индексе), latency (forward-pass большой модели) и деньги (GPU под нагрузкой или счет за эмбеддинг-API). И если latency лечится инференс-стеком (SGLang, батчинг - тема будущей статьи серии), то стоимость индекса растет линейно с числом документов и не лечится ничем, кроме сжатия векторовПример, чтобы почувствовать масштаб. Qwen3-Embedding отдаёт вектор на 1024 измерения (у 8B — до 4096).
Технические детали
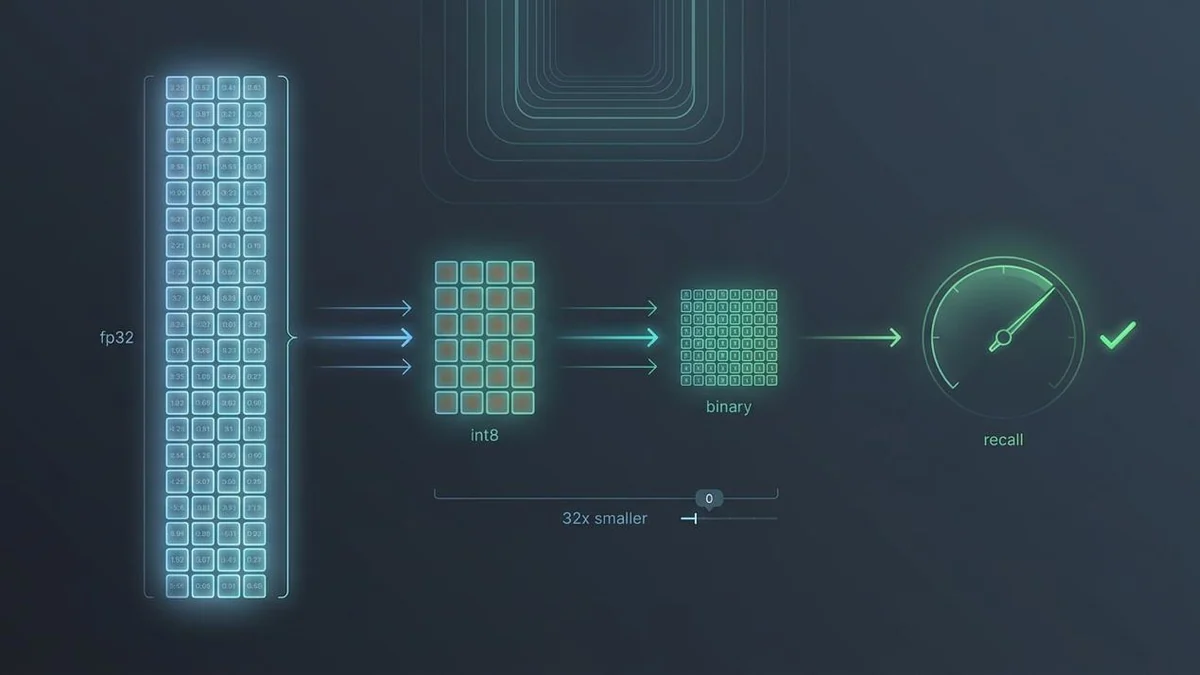
Возьмём типичный корпус на 100М чанков и вектор 1024-dim в fp32:100_000_000 × 1024 × 4 байта = 409 ГБ409 гигабайт только под сырые векторы, без HNSW-графа сверху (а он добавляет еще 30-50%). Это уже не влезает в один узел и стоит ощутимых денег в час. Тот же индекс после агрессивного сжатия - единицы гигабайт.
Вопрос не в том, сжимать ли. Вопрос - где точка невозврата по recallВ этой статье разберем все оси сжатия, посмотрим на реальные замеры, где качество деградирует мягко, а где обрывается в пропасть, и вас ждет воспроизводимый скрипт + Colab-ноутбук, чтобы вы прогнали то же самое на своих векторах, если будет интересно. > Весь код и данные для воспроизведения - в конце статьи.
Скрипт compress_experiment. py принимает вашу матрицу эмбеддингов и измеряет все, что ниже, на CPU. Colab-ноутбук делает то же самое на реальной Qwen3-Embedding-0.
Отраслевые последствия
6B - free-версии T4 хватаетТри оси сжатия (и почему их путают)Когда говорят «сжать эмбеддер», обычно смешивают три независимые вещи, которые работают на разных уровнях:1. Дистилляция - сжимаем саму модель. Учим маленькую модель (0.
6B) воспроизводить эмбеддинги большой (8B). Уменьшается вес модели, latency инференса и, косвенно, размерность вектора. Это самый дорогой путь: нужен свой датасет и обучение.
Дистилляцию я оставлю за скобками - она смыкается с файнтюном эмбеддера, а это достойно отдельных статей2. Квантизация - сжимаем точность чисел в векторе. Вектор остается той же размерности, но каждое число хранится не в fp32 (4 байта), а в int8 (1 байт), int4 (полбайта) или вообще в 1 бите.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.




