Как мы строим корпоративную экзаменационную платформу с AI: архитектура, дубли, мульти-tenant и продовые шишки
azamat_sandboxer 10 минут назад Как мы строим корпоративную экзаменационную платформу с AI: архитектура, дубли, мульти-tenant и продовые шишки Средний 5 мин 310 Блог компании Sandboxer Python * Машинное обучение *...
Anthropic — What company has the best second artificial intelligence model at the end of June?
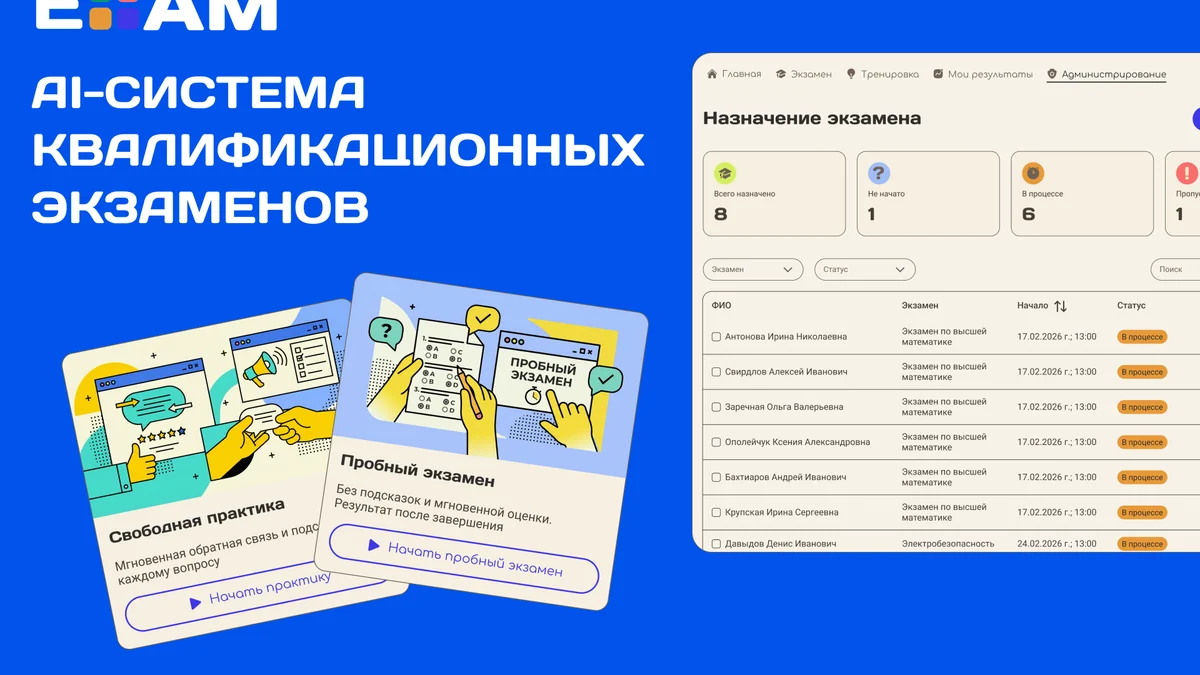
В сфере искусственного интеллекта произошло заметное событие. azamat_sandboxer 10 минут назад Как мы строим корпоративную экзаменационную платформу с AI: архитектура, дубли, мульти-tenant и продовые шишки Средний 5 мин 310 Блог компании Sandboxer Python * Машинное обучение * Искусственный интеллект ReactJS * Кейс Привет, Хабр. Хочу рассказать про наш проект Exam AI — внутреннюю платформу для аттестации и тренировки сотрудников. Это не “ещё один тестик на 20 вопросов”, а система, где:контент живёт в управляемом банке вопросов;вопросы можно генерировать из нормативных документов через LLM;экзамен идёт как stateful runtime со сложным сценарием;есть роли, назначения, апелляции, аналитика и multi-tenant модель организаций.
Текст будет не маркетинговый. Больше про инженерные решения, компромиссы и то, что реально ломалось. Что мы решалиВо многих компаниях подготовка экзаменов выглядит примерно так:Появился новый регламент.
Технические детали
Методист руками пишет вопросы. Дальше вручную правит формулировки, удаляет дубли и снова согласует. Проблемы понятны:долго;дорого;плохо масштабируется;при изменении документов весь цикл почти с нуля.
Наша цель была прагматичной: сократить путь “документ -> экзамен”, но не потерять контроль качества. То есть не “отдать всё ИИ”, а сделать управляемый конвейер. Технический контурBackendPython 3.
14FastAPISQLAlchemy 2 (async) + PostgreSQLpgvector для эмбеддинговpydantic-ai / Pydantic modelsTaskIQ + Redis для фоновых задачMinIO для медиаFrontendReact 19 + TypeScriptViteTanStack QueryZustandxState 5 (runtime flow)Orval (генерация API-клиента из OpenAPI)Tailwind + DaisyUIИнфраструктураOIDC/SSO (Keycloak через внутренний SDK)Docker / TraefikCI с quality/security гейтамиПочему DDD-слои реально помоглиНа backend мы изначально держали жёсткое разделение:domain — сущности, value objects, протоколы;application — use cases;infrastructure — репозитории, внешние адаптеры, агенты;presentation — API/схемы. Это банально звучит, но на длинной дистанции спасает. Когда у тебя появляется:новый источник контента;новый LLM-провайдер;новый вариант scoring/validation;ты меняешь адаптеры и оркестрацию, а не переписываешь всё ядро.
Отраслевые последствия
AI-генерация: почему “просто попросить модель” не работаетПервая ошибка, которую мы (как и многие) сделали: “Дадим модели большой документ и попросим сгенерировать N вопросов”. Результат:тематические перекосы;поверхностные вопросы;дубли в разных формулировках;плохая воспроизводимость между запусками. Поэтому мы перешли к пайплайну с явными стадиями.
1) ScanДокумент режется на фрагменты, строятся эмбеддинги, формируется карта тем. 2) PlanПланируем генерацию как отдельный шаг:сколько вопросов на тему;какой тип контента;приоритеты;какие области знаний покрываем. 3) GenerateГенерируем не свободный текст, а строго типизированную структуру (Pydantic-схемы).
Невалидный ответ -> retry с уточнением требований. 4) ValidateАвтопроверки кандидатов:semantic near-duplicate;валидность ожидаемого ответа;привязка к knowledge area;проверка формата/полноты. 5) ReviewПоследнее слово у эксперта: approve/edit/reject.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.