Как я собрал эталонный Data Engineering проект: ClickHouse, Kafka, Spark, dbt, Airflow и Superset за одну команду
GenomeDust 36 минут назад Как я собрал эталонный Data Engineering проект: ClickHouse, Kafka, Spark, dbt, Airflow и Superset за одну команду Средний 10 мин 888 Data Engineering * Data Mining * Криптовалюты Big Data *...
Anthropic — What company has the best second artificial intelligence model at the end of June?
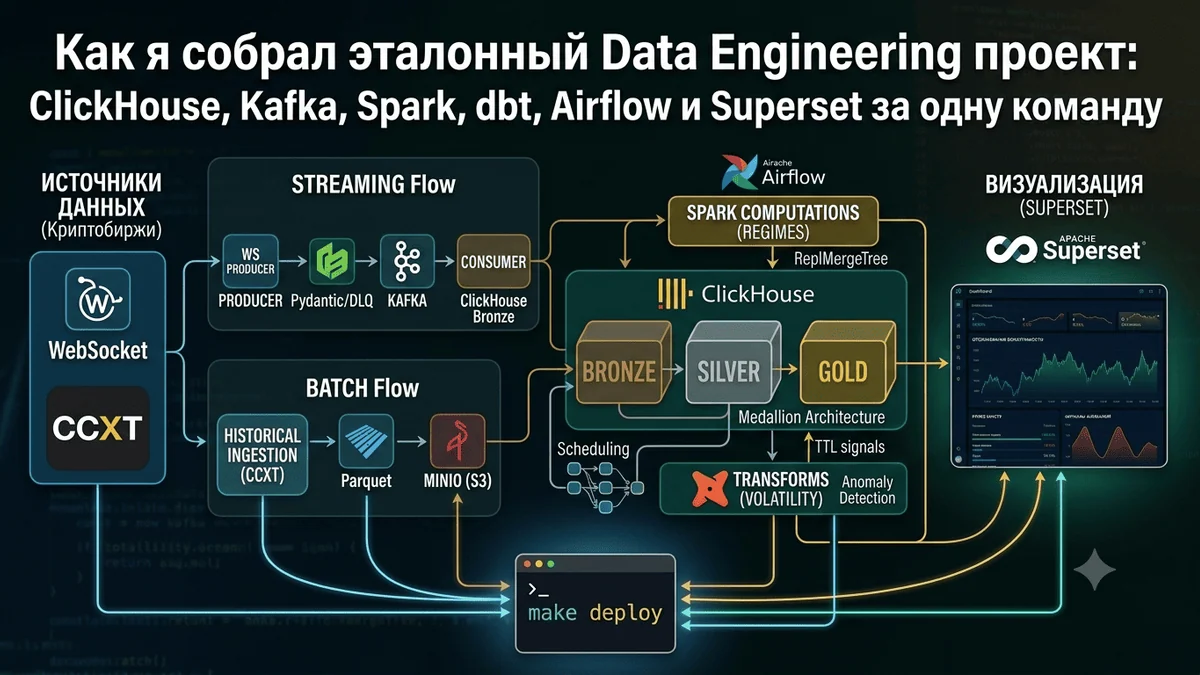
Вот важная новость с фронта ИИ: GenomeDust 36 минут назад Как я собрал эталонный Data Engineering проект: ClickHouse, Kafka, Spark, dbt, Airflow и Superset за одну команду Средний 10 мин 888 Data Engineering * Data Mining * Криптовалюты Big Data * Туториал Когда я искал учебные проекты по data engineering, картина была примерно одинаковой: либо туториал на два инструмента («пишем в Kafka, читаем в Spark»), либо enterprise-схема без единой строчки кода. Мне хотелось чего-то среднего — реальный стек, реальные данные, реальные проблемы, но при этом всё поднимается одной командой make deploy без предварительной настройки. Результат: платформа сбора и анализа криптовалютных данных, которую можно склонировать и запустить на любой машине с Docker.
В этой статье расскажу об архитектуре, интересных технических решениях и граблях, которые встретились по пути. Что получилосьПеречислю сначала, что делает система:Скачивает 30 дней истории по 5 символам (BTC/ETH/SOL/BNB/XRP) в момент деплояСтримит live-данные с Binance через WebSocket в реальном времениОбнаруживает аномалии: всплески объёма и аномально крупные свечиВычисляет rolling volatility и классифицирует рыночные режимы через Apache SparkСобирает всё на аналитическом дашборде — тоже автоматическиИ весь этот стек поднимается командой:git clone cd Crypto-Research-Workbench make deploy Пароли генерируются автоматически, все сервисы настраиваются сами. Технологический стек и почему именно онСлойИнструментЗачемАналитическая СУБДClickHouse 23.
Технические детали
8Колоночная БД, агрегации в 10–100× быстрее PostgreSQLОбъектное хранилищеMinIOS3-совместимое хранилище — тот же код работает в AWSОчередьApache KafkaAt-least-once delivery, replay данных, развязка producer/consumerBatch-обработкаApache Spark 3. 5Горизонтальное масштабирование для тяжёлых вычисленийТрансформацииdbt 1. 7 + ClickHouseSQL с тестами, lineage, документациейОркестрацияApache Airflow 2.
8Расписание, мониторинг, retryBIApache Superset 3. 0ДашбордыКонтейнеризацияDocker Compose v2Весь стек одной командойПочему ClickHouse, а не PostgreSQL для аналитики? PostgreSQL — строчная СУБД.
На запросе SELECT AVG(close) FROM klines GROUP BY symbol, date он читает все колонки каждой строки. ClickHouse читает только колонки close, symbol, open_time — остальные физически не трогает. На таблице в 200k строк разница незаметна.
Отраслевые последствия
На таблице в 200 млн — принципиальна. Почему MinIO, а не просто диск? MinIO реализует S3 API.
Код, который пишет в MinIO, без изменений запишет в AWS S3 — достаточно поменять endpoint в . Это принципиально для production-ready архитектуры. Почему dbt И Spark одновременно?
Это не дублирование, а разделение ответственности:dbt — SQL-трансформации в ClickHouse: ETL, агрегации, обогащение данных. Просто, тестируемо, быстро разрабатывается. Spark — для задач, которые горизонтально масштабируются: rolling window по 90 дням минутных свечей по всем символам.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.



