Самый старый кирпич трансформера наконец переизобрели. DeepSeek взял матрицу из 1967 года
niktomimo 34 минуты назад Самый старый кирпич трансформера наконец переизобрели. DeepSeek взял матрицу из 1967 года Сложный 5 мин 1.7K Машинное обучение * Искусственный интеллект Natural Language Processing * Алгоритмы...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
В сфере искусственного интеллекта произошло заметное событие. niktomimo 34 минуты назад Самый старый кирпич трансформера наконец переизобрели. DeepSeek взял матрицу из 1967 года Сложный 5 мин 1. 7K Машинное обучение * Искусственный интеллект Natural Language Processing * Алгоритмы * Математика * Аналитика За attention-механизм с 2017 года брались сотни раз: sparse attention, linear attention, MoE, MLA, скользящие окна, что только не.
А вот residual connection, остаточная связь, та самая x + F(x) из ResNet 2016 года, простояла почти десять лет нетронутой. Её просто унаследовали из résnet'ов, воткнули в трансформер и забыли. 31 декабря 2025-го DeepSeek выложил на arXiv препринт, где взялся именно за этот кирпич.
Технические детали
И что показательно, загрузил его на arXiv лично основатель компании Liang Wenfeng, он же в соавторах. Когда основатель сам публикует статью, это обычно значит, что она ляжет в следующую флагманскую модель. Так и вышло: mHC поехал в DeepSeek V4, который выкатили 24 апреля 2026-го.
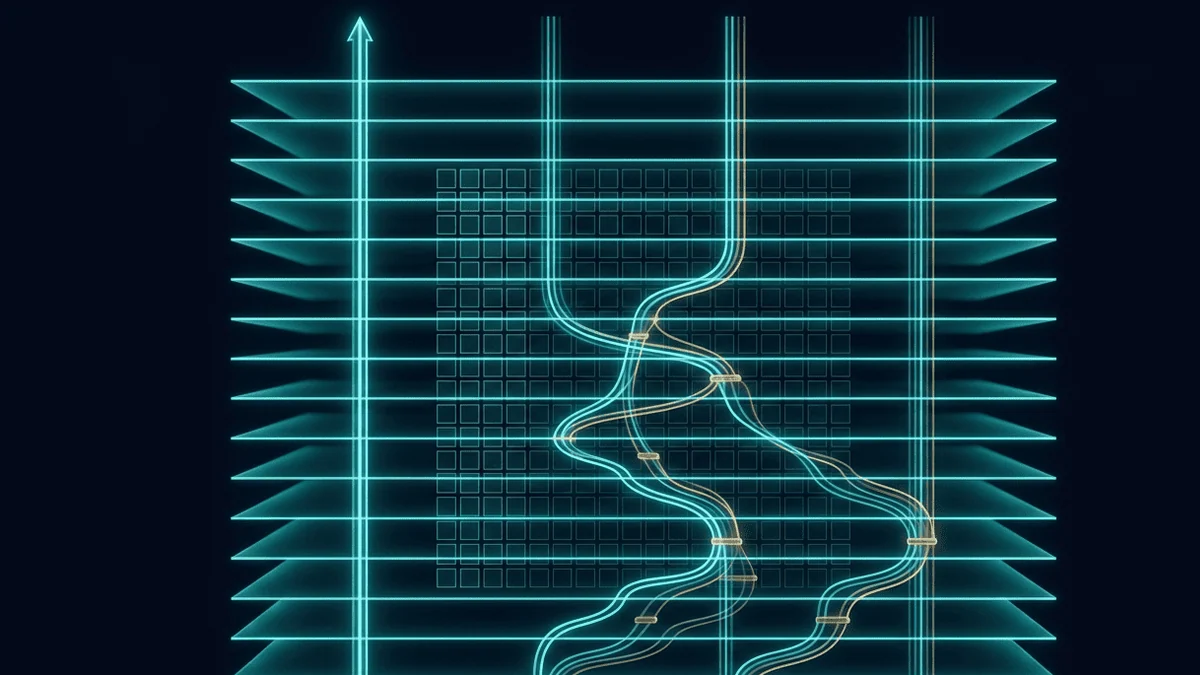
Разберём, что они сделали, почему это работает и при чём тут матрица из шестидесятых. Зачем вообще трогать residualСначала освежим, что делает остаточная связь, иначе мотивация не считывается. До residual-связей глубокие сети было тяжело обучать.
Сигнал проходит через много слоёв и постепенно затухает, градиент по дороге назад тоже. ResNet починил это одной идеей: вместо того чтобы прогонять вход только через сложное преобразование, оставляем рядом чистый обход. Вход x перепрыгивает слой и складывается с его выходом: = x_l + F(x_l).
Отраслевые последствия
Магия тут в identity mapping. Если слой F ничего полезного не выучил, исходный сигнал всё равно проходит дальше без изменений. К функции, которую мы оптимизируем, добавляется тождественное отображение с постоянным градиентом 1.
Это гасит проблему затухающих градиентов: даже когда градиент F уезжает близко к нулю, единица от identity-ветки держит поток. Именно это сделало обучение очень глубоких сетей практичным. Внутри F за десять лет накрутили всё что можно.
А сама остаточная связь так и осталась одним сложением. DeepSeek решил, что там есть что улучшить. Hyper-Connections: больше выразительности, меньше стабильностиОтправная точка для DeepSeek, это статья Hyper-Connections от ByteDance 2025 года.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.




