DRAйверы для GPU: как Kubernetes научился выделять устройства через стандартный API
Myskat_90 только что DRAйверы для GPU: как Kubernetes научился выделять устройства через стандартный API Сложный 20 мин 28 Блог компании Флант Искусственный интеллект Kubernetes * IT-инфраструктура * Видеокарты Dynamic...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
Значимый прорыв формирует отрасль ИИ: Myskat_90 только что DRAйверы для GPU: как Kubernetes научился выделять устройства через стандартный API Сложный 20 мин 28 Блог компании Флант Искусственный интеллект Kubernetes * IT-инфраструктура * Видеокарты Dynamic Resource Allocation — это стандартный механизм Kubernetes для запроса и совместного использования устройств. Он даёт фильтрацию по атрибутам (CEL), шаринг, централизованные классы устройств и более правильный рабочий процесс, чем device plugins. Но при этом DRA — это не один переключатель.
Внутри него есть фичи с разными стадиями (stable/beta/alpha), и миграция с device plugins на DRA должна идти по ступеням. В первой статье мы разобрали, почему device plugin рано или поздно упирается в потолок, если вы строите коммунальный кластер с продом, обучением и кучей разношёрстных нагрузок, а не используете GPU для одной команды. В этой же статье я хочу сделать три вещи:Показать, что именно Kubernetes добавил вместе с DRA и почему это действительно меняет модель управления устройствами.
Технические детали
Разложить реальный путь миграции с device plugin на примере коммунального кластера на H100, чтобы переход не выглядел как проект «переписать половину манифестов и заодно придумать новую религию». Рассказать, почему мы делаем свой DRA-драйвер в Deckhouse Kubernetes Platform, а не берём готовые. Меня по-прежнему зовут Александр Подмосковный, и я менеджер продукта в команде Deckhouse Kubernetes Platform, где развиваю направление ML/AI.
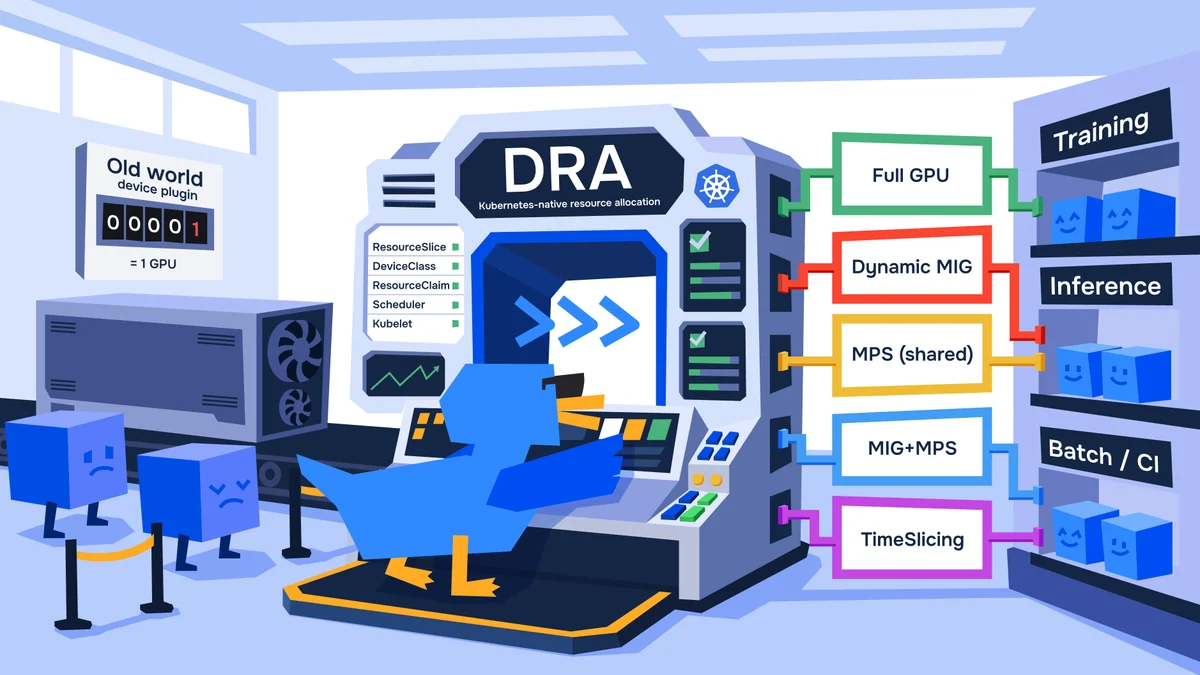
Погнали разбираться с возможностями, которые даёт DRA. Когда один кластер обслуживает разные классы нагрузок: 8 узлов × 8 видеокарт H100Представим, что у нас есть общий кластер для нескольких команд:8 GPU-узлов;на каждом по 8 × NVIDIA H100 80GB;всего 64 GPU. Внутри кластера живут три класса нагрузок:ML-обучение и эксперименты — им нужны «честные» карты и предсказуемость;продовый инференс — много сервисов, которым часто не нужна вся H100;короткие GPU-задачи — CI, профилировки, batch inference, эпизодические нагрузки.
В device-plugin-модели все они упираются в один и тот же примитив: «дай N устройств». А дальше начинается отдельная инженерная жизнь: Multi-Instance GPU, time-slicing, Multi-Process Service, scheduler-extender, очереди, пулы, правила, исключения. Именно здесь на сцену выходит DRA.
Короткая и полезная мысль про DRADynamic Resource Allocation делает с устройствами примерно то же, что Kubernetes когда-то сделал с хранилищем:раньше диск «как-то» подключали;потом появились StorageClass и PersistentVolumeClaim;и дальше стало проще строить платформу, а не систему договорённостей. В документации Kubernetes DRA прямо сравнивают с динамическим выделением томов. Device drivers и администраторы описывают классы устройств, DRA-драйвер публикует инвентарь, а Kubernetes подбирает устройство под конкретную заявку пользователя и размещает под там, где оно доступно.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.




