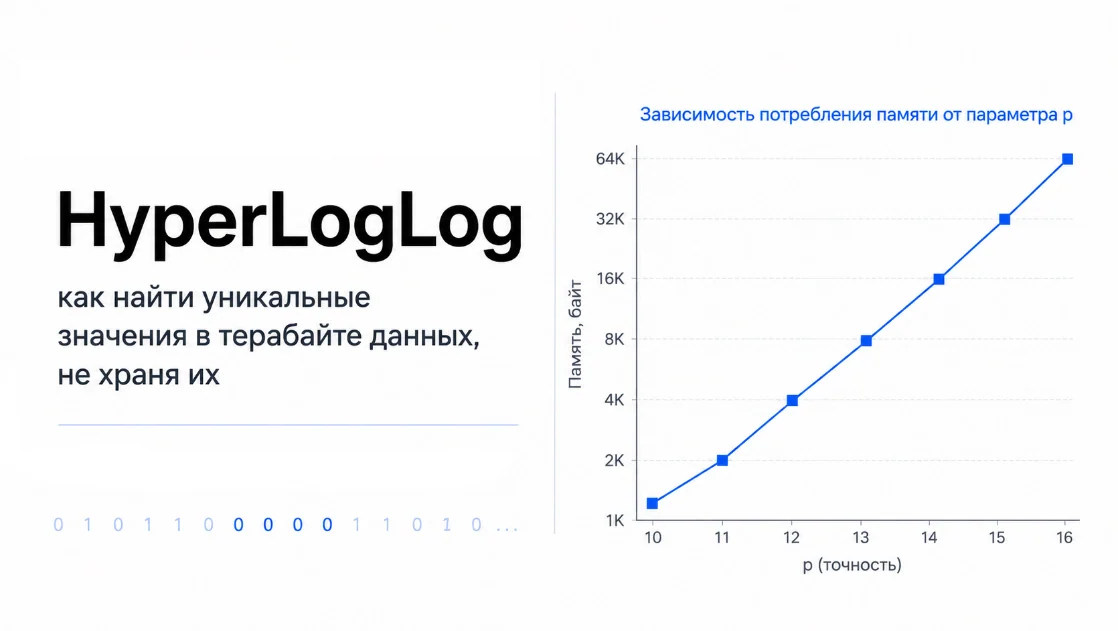
Сколько стоит контекст для кодового агента: grep vs граф vs LSP на большом проекте (936 прогонов)
Neko1313 3 минуты назад Сколько стоит контекст для кодового агента: grep vs граф vs LSP на большом проекте (936 прогонов) Средний 11 мин 0 Python * Машинное обучение * Искусственный интеллект Анализ и проектирование...
Anthropic — What company has the best second artificial intelligence model at the end of June?
В сфере искусственного интеллекта произошло заметное событие. Neko1313 3 минуты назад Сколько стоит контекст для кодового агента: grep vs граф vs LSP на большом проекте (936 прогонов) Средний 11 мин 0 Python * Машинное обучение * Искусственный интеллект Анализ и проектирование систем * Open source * Аналитика Продолжение статьи про graphlens. Там я описал, что инструмент делает и как устроен, и по дороге уверенно заявил, что «агент жжёт токены, бегая grep'ом по репозиторию». Заявил — но ни одной цифры не привёл.
Эта статья закрывает дыру: вот замеры, вот данные, вот воспроизводимый стенд. Спойлер: вывод оказался не таким, каким я его себе рисовал, и это самое интересное. КороткоЯ взял одного и того же агента (Claude Code), менял у него ровно одну вещь — какой MCP-сервер отдаёт контекст по коду, — и гонял по 26 задачам на apache/superset.
Технические детали
Четыре «руки»: filesystem (grep + read), graphlens (структурный граф), serena (LSP) и codegraph. Три модели (haiku / sonnet / opus), три сида — 936 прогонов. Главный результат: вывод переворачивается в зависимости от типа задачи.
На простых «где определён X / от чего наследуется» — все четыре инструмента равны по точности, разница только в цене (~3×). graphlens тут ничем не выделяется. На задачах «оцени радиус поражения / найди все переопределения / разреши неоднозначное имя» инструменты резко расходятся: grep разваливается (точность 0.
71, до финиша доходит 83% прогонов, а те, что доходят, стоят в 10–23 раза дороже), а структурные инструменты остаются дешёвыми и точными. Если бы я мерил только простые задачи, я бы написал «граф не нужен, grep справляется». Если бы только сложные — «grep не нужен, берите граф».
Отраслевые последствия
Правда — посередине, и она про то, какую работу вы поручаете агенту. Бизнес-кейс, который мы на самом деле измеряемПредставьте типичную ситуацию. Есть большой проект: сотни тысяч строк, бэкенд на Python, фронт на TypeScript, легаси, в которое страшно лезть.
Вы подключаете к нему кодового агента — для ревью, для рефакторинга, для ответов на вопросы вроде «что сломается, если я поменяю сигнатуру вот этого метода». Агент не видит весь репозиторий разом. Кто-то должен подавать ему контекст: какие функции где определены, кто кого вызывает, что от чего наследуется.
И вот тут возникает архитектурное решение, у которого есть цена: чем именно кормить агента? Вариантов, по сути, четыре класса:Дать ему grep и read — пусть ищет текстом и читает файлы. Ноль инфраструктуры, работает везде.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.