Топ вопросов по LLM: стратегии генерации текста и метрики оценки LLM
abletobetable 7 минут назад Топ вопросов по LLM: стратегии генерации текста и метрики оценки LLM Средний 17 мин 108 Машинное обучение * Искусственный интеллект Natural Language Processing * Обзор На...
Anthropic — What company has the best second artificial intelligence model at the end of June?
Вот важная новость с фронта ИИ: abletobetable 7 минут назад Топ вопросов по LLM: стратегии генерации текста и метрики оценки LLM Средний 17 мин 108 Машинное обучение * Искусственный интеллект Natural Language Processing * Обзор На NLP/LLM-собеседованиях часто проверяют не то, знаешь ли ты слова top-k, top-p и BLEU, а понимаешь ли ты, что происходит с распределением вероятностей, почему greedy decoding зацикливается, зачем нужна temperature и почему BLEU плохо оценивает ответы современных LLM. В этой статье - чеклист по языковому моделированию, стратегиям генерации и метрикам качества. Это не полноценная лекция с нуля, а тренажёр, по которому стоит пройтись перед техническим интервью по NLP, чтобы закрыть пробелы и вспомнить необходимую базу.
Содержание:Языковое моделированиеСтратегии генерации текстаМетрики оценки качества сгенерированного текстаИтоговый чеклист вопросов с собесовПолезные материалыСтатьи серииТоп вопросов по математике для ML и Data Science собесов: линейная алгебра и матанclassic ML: основы мл, линейные модели, метрики классификации и регресииclassic ML: Деревья и ансамбли, кластеризация, метрические моделиNLP: трансформеры и вниманиеNLP: языковое моделирование, LLM Alignment и оптимизация трансформеров NLP: GPT, LLM, Alignment и оптимизации NLP: LLM и агенты NLP: LLM и RAGЯзыковое моделированиеЧто такое задача языкового моделирования? Языковое моделирование - это фундаментальная задача NLP, в которой модель учится оценивать вероятность последовательности токенов. Модель оценивает совместную вероятность последовательности через chain rule:То есть модель учится предсказывать каждый следующий токен по предыдущему контексту, и мы раскладываем вероятность всего предложения на произведение условных вероятностей следующего токена.
Технические детали
Пример предсказания следующего токенаМодель учится на огромном количестве текстов предсказывать статистически и семантически подходящее продолжение. Именно это лежит в основе современных GPT-like моделей. Где встречается языковое моделирование?
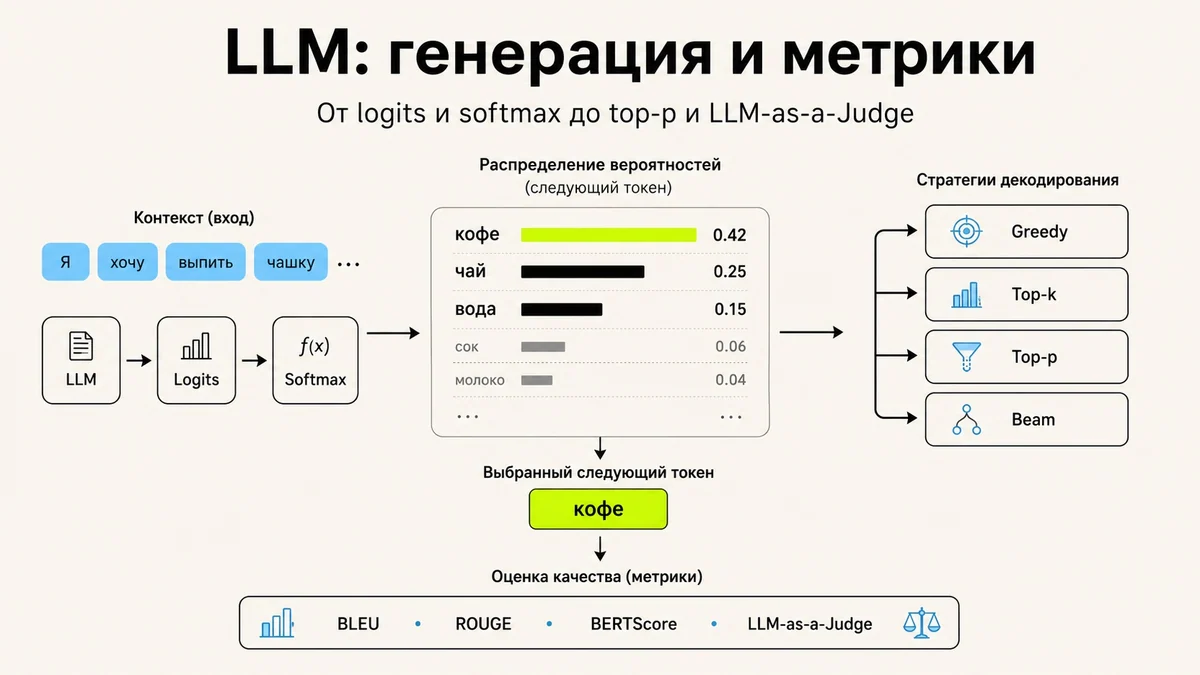
автодополнение в клавиатуреподсказки в поисковикемашинный переводгенерация ответов в чат-ботахсуммаризация текстовгенерация кодаисправление ошибокпродолжение текстапереформулированиегенерация описаний товаровПримеры применения языковых моделейТо есть задача вроде бы простая - предсказывать следующий токен, но на ней строится почти все современное генеративное NLP. Как модель получает вероятность следующего токена? Упрощённый пайплайн выглядит так:Берём текстРазбиваем его на токеныПревращаем токены в эмбеддингиПропускаем эмбеддинги через нейронную сетьПолучаем hidden stateПрогоняем hidden state через линейный слойПолучаем логиты по словарюПрименяем softmaxПолучаем распределение вероятностей следующего токенаДопустим, у модели словарь из 50 000 токенов.
Тогда на каждом шаге генерации модель должна выдать распределение вероятностей по всем этим 50 000 возможным токенам. Например:ТокенВероятностькофе0.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.