Как строить отказоустойчивые кластеры Kubernetes: краткий разбор от команды VK Cloud
GRADDATA 37 минут назад Как строить отказоустойчивые кластеры Kubernetes: краткий разбор от команды VK Cloud Простой 8 мин 1.1K Блог компании VK Tech Блог компании VK Kubernetes * DevOps * IT-инфраструктура * Обзор...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
Значимый прорыв формирует отрасль ИИ: GRADDATA 37 минут назад Как строить отказоустойчивые кластеры Kubernetes: краткий разбор от команды VK Cloud Простой 8 мин 1. 1K Блог компании VK Tech Блог компании VK Kubernetes * DevOps * IT-инфраструктура * Обзор Миграция в облако и переход к микросервисной архитектуре сделали Kubernetes (k8s) де-факто стандартом для управления контейнерами. По данным 2025 года, технологию уже применяют 60% крупных российских компаний, а ещё 15% планируют внедрение в будущем.
Причем 59% компаний называют отказоустойчивость ключевым критерием при выборе Kubernetes, но лишь единицы реализуют его на практике. Проблема кроется в недооценке системных рисков — от отсутствия резервирования control plane до некорректных таймингов readiness-проб, пропускающих «полуживые» поды в балансировщик. В этой статье мы кратко разберем ключевые принципы проектирования и эксплуатации отказоустойчивых кластеров, типовые сценарии сбоев и рекомендации по исключению рисков на всех уровнях.
Технические детали
Развернутый анализ с практическими рекомендациями по настройке, готовыми примерами команд для проверки состояния кластера и чек-листом можно найти в бесплатном гайде «Отказоустойчивость в Kubernetes» от команды VK Cloud. О Kubernetes и отказоустойчивости Kubernetes — система оркестрации контейнеров, предназначенная для автоматизации развёртывания, масштабирования и управления контейнеризированными приложениями. это платформа, которая берёт на себя всю рутину по управлению жизненным циклом приложений: она решает, на каком сервере запустить контейнер, следит за его состоянием, обеспечивает сетевое взаимодействие между различными компонентами системы, поддерживает отказоустойчивость.
Так, Kubernetes по умолчанию обеспечивает отказоустойчивость платформы, но не запущенного на ней сервиса. То есть даже идеально работающий кластер не спасёт приложение, если у него есть одиночная точка отказа, например, база данных без failover-механизма. Поэтому для обеспечения стабильности всей системы недостаточно только встроенных механизмов k8s — необходимо предусматривать меры, способные гарантировать доступность и отказоустойчивость на всех уровнях и этапах: от инфраструктуры до эксплуатации.
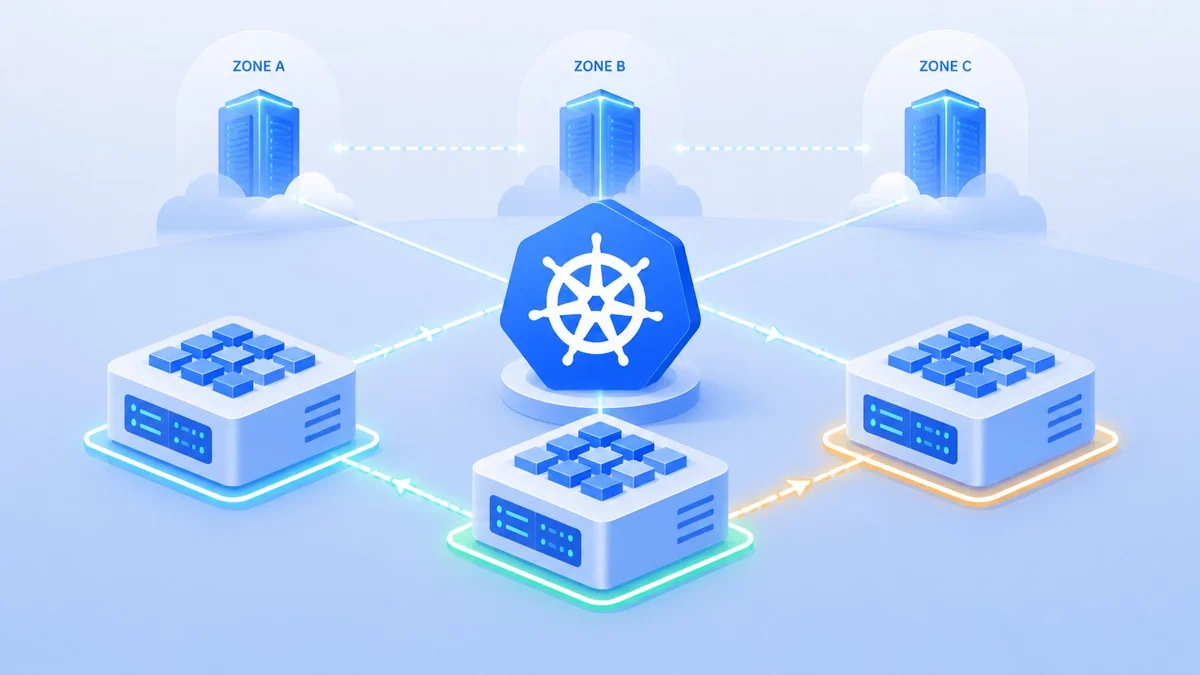
На каждом из них остановимся подробнее. Меры обеспечения отказоустойчивости на уровне инфраструктурыОтказоустойчивость начинается с площадки, на которой развернут Kubernetes — если фундамент треснет, то никакая автоматика не спасет. Главная цель здесь — исключить единую точку отказа (Single Point of Failure, SPOF) на уровне физического или виртуального оборудования.
Отраслевые последствия
Корректная работа с инфраструктурой для обеспечения отказоустойчивости предполагает несколько мер. Использование нескольких зон доступности (AZ). Размещение всех узлов кластера в одной «корзине» недопустимо — при сбое питания или сети в одной зоне весь сервис станет недоступен.
Для базовой отказоустойчивости используется минимум две зоны, для production-систем — три. Обеспечение нечётного количества узлов для etcd в разных доменах отказа.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.




