Масштабирование LLM: от одного чипа до ЦОДа. Глава 2. Шардинг
Это продолжение цикла статей о масштабировании тренировки и инференса LLM. Предыдущая глава находится по этой ссылке.Итак, с основами разобрались, давайте теперь разбираться с тем, как распихать матрицы по нескольким...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
Значимый прорыв формирует отрасль ИИ: Это продолжение цикла статей о масштабировании тренировки и инференса LLM. Предыдущая глава находится по этой ссылке.
Итак, с основами разобрались, давайте теперь разбираться с тем, как распихать матрицы по нескольким чипам, перемножить, а затем собрать это все в удобоваримый результат. По-умному это называется шардинг.
Технические детали
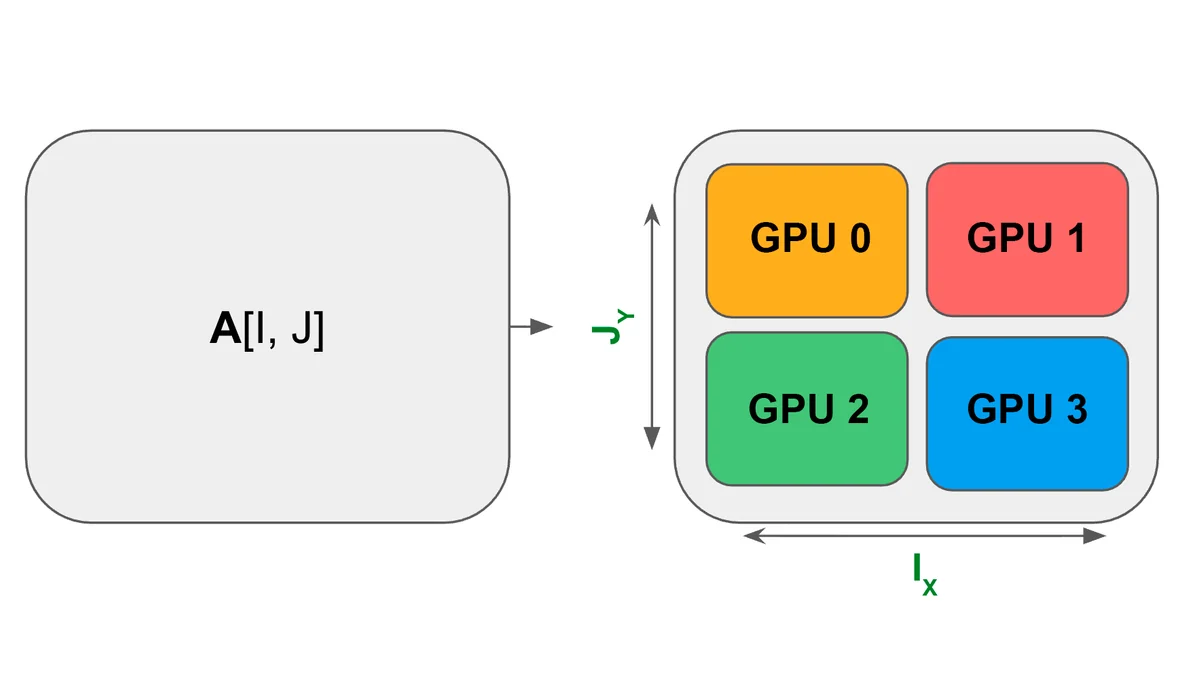
Для начала давайте определимся, зачем этот шардинг вообще нужен. А нужен он потому что, как я уже писал в предыдущей статье, при работе с действительно большими нейронками матрицы и вектора практически никогда целиком не влезают в память одного GPU/TPU, поэтому их приходится разделять или шардировать.
От того, насколько грамотно произведен шардинг, зависит то, насколько эффективно используется наш массив ускорителей, а следовательно и скорость тренировки, эффективность расхода вычислительных ресурсов и т.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.




