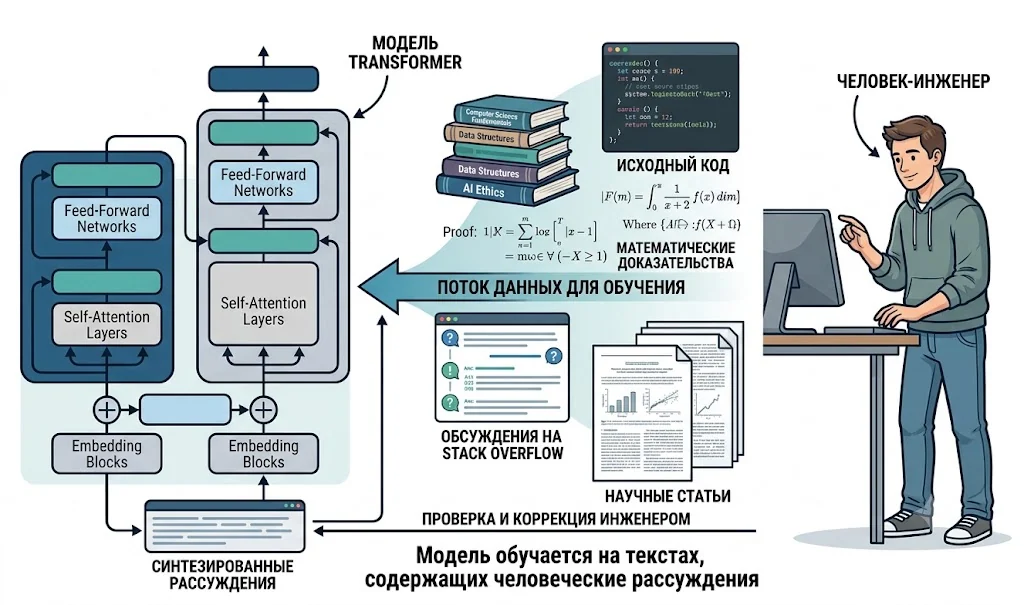
Как думает LLM: строим ChatGPT с нуля за десять шагов
amaksr 7 минут назад Как думает LLM: строим ChatGPT с нуля за десять шагов 8 мин 96 Искусственный интеллект Когда впервые сталкиваешься с современными языковыми моделями, легко потеряться в количестве новых терминов....
Anthropic — What company has the best second artificial intelligence model at the end of June?
В сфере искусственного интеллекта произошло заметное событие. amaksr 7 минут назад Как думает LLM: строим ChatGPT с нуля за десять шагов 8 мин 96 Искусственный интеллект Когда впервые сталкиваешься с современными языковыми моделями, легко потеряться в количестве новых терминов. Embeddings, Attention, KV Cache, Multi-Head Attention, Positional Encoding — в статьях про GPT и Llama всё это появляется уже на первых страницах. Проблема в том, что большинство объяснений начинают сразу с Transformer — архитектуры, которая сама по себе состоит из множества идей, накопленных за годы развития нейросетей.
В результате читателю приходится разбираться одновременно и с механизмом внимания, и с эмбеддингами, и с особенностями обучения больших моделей. Гораздо проще посмотреть на этот путь шаг за шагом:Bigram model ↓ RNN ↓ Attention ↓ Transformer ↓ LLMКаждая новая архитектура появлялась не на пустом месте, а как ответ на ограничения предыдущей. Если проследить эту цепочку целиком, многие идеи современных LLM начинают выглядеть гораздо менее загадочными.
Технические детали
Transformer оказывается логичным развитием более ранних подходов, а большие языковые модели — результатом постепенного накопления инженерных решений, а не внезапного технологического скачка. Как устроен LLMШаг 1. Bigram Model: попугай на 49 параметровНачнем с максимально простой языковой модели.
Пусть наш словарь состоит всего из семи токенов:vocab = [ "John", "Mary", "likes", "hates", "cats", "dogs", "" ]Обучающие данные:John likes cats John likes dogs Mary likes cats Mary hates dogsСамая простая языковая модель хранит вероятность следующего токена после текущего. Например:P(likes | John) P(hates | Mary) P(cats | likes) P(dogs | hates)Такую модель можно представить как матрицу:import numpy as np vocab_size = 7 weights = np. randn(vocab_size, vocab_size) print(weights.
shape)Результат:(7, 7)Всего:7 × 7 = 49 параметровДля генерации текста используется Softmax. # превращает произвольные числовые оценки модели в вероятности, # сумма которых равна 1 def softmax(x): e = np. max(x)) return e / e.
Отраслевые последствия
sum() john_id = 0 probs = softmax(weights) print(probs)Теперь модель умеет отвечать на вопрос:Какой токен вероятнее всего идет после "John"? Это уже настоящий Language Model. Но есть проблема: после слова "likes" модель не помнит, кто именно любит кошек.
John likes cats Mary likes catsДля нее это одна и та же ситуация, так как памяти нет. RNN (Recurrent Neural Network): добавляем памятьЛогичное решение — хранить внутреннее состояние. Пусть модель читает предложение по одному слову.
John → likes → catsПосле каждого токена обновляется скрытое состояние. import numpy as np # В начале предложения память пустая h = np. zeros(2) # Параметры модели, которые будут обучаться Wx = np.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.