Разбираемся в ML без воды: от базы до Attention. Часть 9: Дерево решений
ysrgsyn 9 минут назад Разбираемся в ML без воды: от базы до Attention. Часть 9: Дерево решений Простой 12 мин 193 Математика * Машинное обучение * Python * В восьмой части мы завершили изучение SVM и разобрались с...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
В сфере искусственного интеллекта произошло заметное событие. ysrgsyn 9 минут назад Разбираемся в ML без воды: от базы до Attention. Часть 9: Дерево решений Простой 12 мин 193 Математика * Машинное обучение * Python * В восьмой части мы завершили изучение SVM и разобрались с Kernel Trick. Теперь пришло время познакомиться с деревьями решений — одним из самых популярных и интуитивно понятных алгоритмов машинного обучения.
Идея дерева решений достаточно проста. Алгоритм последовательно задаёт вопросы о признаках объекта и, в зависимости от ответов, движется по ветвям дерева, пока не придёт к итоговому решению. Именно благодаря такой структуре деревья решений считаются одними из самых интерпретируемых моделей машинного обучения.
Технические детали
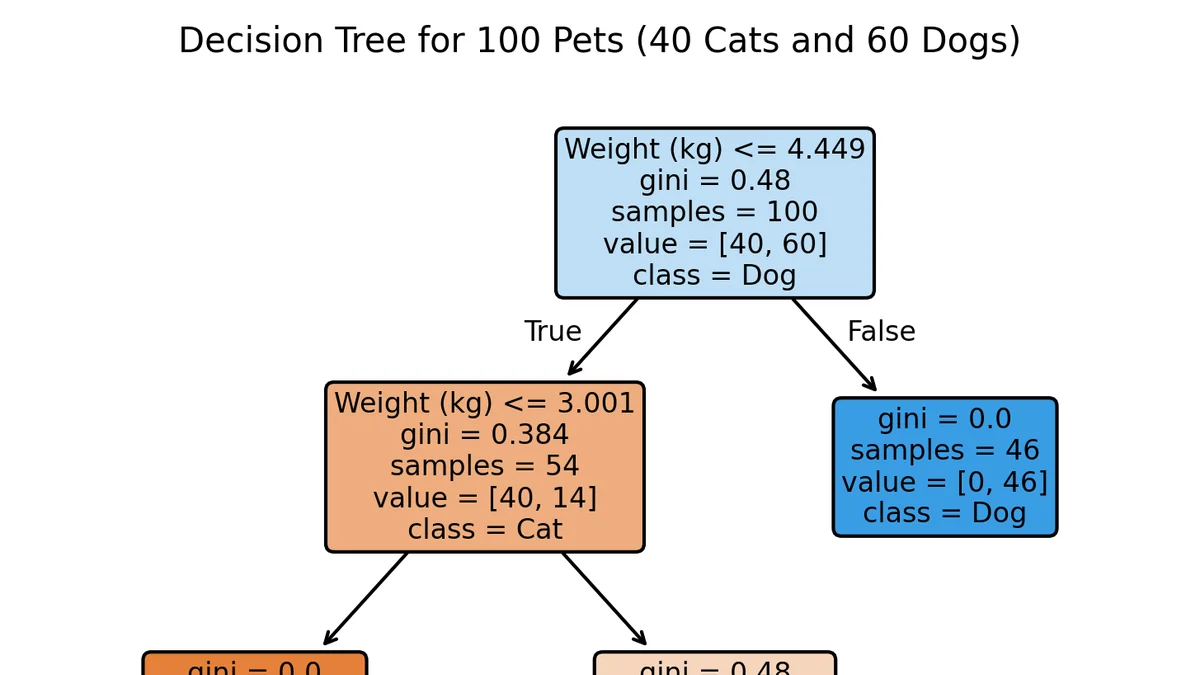
Дерево решений Дерево решений (decision tree) — это модель, которая на каждом шаге делит выборку на подмножества, принимая решение на основе значения одного из признаков. Такое разбиение продолжается рекурсивно: каждая полученная часть снова делится на ещё более мелкие подмножества, пока не будет достигнут некоторый критерий остановки. В конечном счёте множество данных разделяется на подмножества, удовлетворяющие тем или иным правилам разбиения.
Количество таких подмножеств соответствует количеству листьев дерева. Предсказание нового объекта происходит следующим образом: объект проходит последовательность проверок и попадает в соответствующий лист. Для классификации в качестве ответа обычно берут наиболее частый класс в этом листе.
Для регрессии берут среднее значение объектов, попавших в лист. Пример дерева решенийСтроим дерево и измеряем хаосЧто нам хотелось бы? Раз уж мы делим данные на подгруппы, было бы хорошо на каждом шаге выбрать такой признак и такое пороговое значение, которые разделят данные на максимально однородные (чистые) группы.
Отраслевые последствия
В идеале — чтобы в каждом подмножестве оказались объекты только одного класса. Но как компьютеру понять и сравнить, какое разбиение "чище"? Для этого введем критерии информативности, которые измеряют уровень неопределенности или хаоса в данных.
В задачах классификации их два, причем, с одним мы познакомились еще в в шестой части, когда изучали логистическую регрессию и разбирали понятие кросс-энтропии. Entropy (Энтропия Шеннона)Напомню вкратце, что в шестой части мы подробно разбирали, что энтропия — это мера случайности, хаоса или неопределенности распределения. Мы даже считали её на примере монетки: если шансы 50 на 50, энтропия максимальна и равна единице.
Если распределение смещено (0. 1), энтропия падает до 0. 47, так как неопределенности становится меньше.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.




