Одна строка — много объектов: как агрегировать эмбеддинги для ML-моделей
irbix7 16 минут назад Одна строка — много объектов: как агрегировать эмбеддинги для ML-моделей Средний 10 мин 456 Искусственный интеллект Машинное обучение * Туториал Из песочницы КороткоИногда в задаче машинного...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
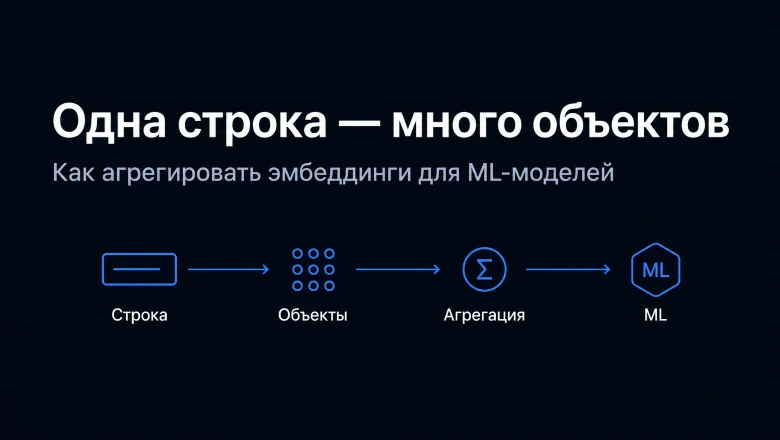
Значимый прорыв формирует отрасль ИИ: irbix7 16 минут назад Одна строка — много объектов: как агрегировать эмбеддинги для ML-моделей Средний 10 мин 456 Искусственный интеллект Машинное обучение * Туториал Из песочницы КороткоИногда в задаче машинного обучения одна строка датасета соответствует не одному объекту, а целому набору связанных объектов. Например:день по акции -> много новостей пользователь -> много комментариев товар -> много фотографий клиент -> много обращений в поддержку сессия -> много событийКаждый такой объект можно представить эмбеддингом. Новость — текстовым эмбеддингом, картинку — визуальным эмбеддингом, событие — вектором признаков или embedding‑представлением.
Но возникает практическая проблема: модель обычно ждет фиксированное число признаков в одной строке, а связанных объектов может быть разное количество. Сегодня у акции 3 новости, завтра 100, послезавтра 0. У одного пользователя 5 комментариев, у другого — 500.
Технические детали
В этой статье я хочу разобрать несколько способов бороться с такой задачей: от простых счетчиков и среднего эмбеддинга до MIL, LLM‑разметки и гибридной схемы, где MIL работает как фильтр перед LLM. Это не статья с бенчмарком и готовыми цифрами качества, а практический обзор подходов, которые можно попробовать в задаче «много объектов на одну строку». Откуда у меня возникла такая задачаС этой проблемой я столкнулся не как с абстрактной задачей, а в довольно практическом контексте.
Я руководил AI‑командами в студенческих проектах НИУ ВШЭ, и в двух командах возникла похожая идея: ребята прогнозировали стоимость акций и хотели учитывать новости. На первый взгляд все звучит логично. Цена акции зависит не только от исторических значений, объема торгов и технических индикаторов.
На нее может влиять информационный фон: отчетность компании, новости о дивидендах, санкции, судебные иски, сделки M&A, смена руководства, изменения в отрасли. Но дальше появляется вопрос: как именно добавить новости в модель? Обычно временной ряд или табличная модель устроены так, что на один объект приходится одна строка фиксированной длины:дата, тикер, цена_вчера, объем_вчера, лаги, день_недели, ...
Отраслевые последствия
А новости устроены иначе:2025-01-01 -> 0 новостей 2025-01-02 -> 7 новостей 2025-01-03 -> 126 новостейЕсли взять эмбеддинг каждой новости, мы получим не один вектор, а набор векторов разной длины. И это уже не ложится напрямую в обычную табличную модель. То есть проблема не в том, чтобы получить эмбеддинг новости.
Проблема в том, как из переменного числа эмбеддингов получить фиксированное представление для одной строки датасета. Почему это не только про новости и акцииНовости для прогноза акций — просто понятный пример. На самом деле такая постановка встречается гораздо шире.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.




