Как я сделал локальный RAG-сервис для SRE: ищем по документации, ранбукам и коду через Ollama
chisi только что Как я сделал локальный RAG-сервис для SRE: ищем по документации, ранбукам и коду через Ollama Средний 6 мин 0 Python * Искусственный интеллект DevOps * Туториал Из песочницы Недавно я делал учебный...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
Значимый прорыв формирует отрасль ИИ: chisi только что Как я сделал локальный RAG-сервис для SRE: ищем по документации, ранбукам и коду через Ollama Средний 6 мин 0 Python * Искусственный интеллект DevOps * Туториал Из песочницы Недавно я делал учебный проект про автоматизацию документирования инцидентов. Поначалу планы были грандиозными: инциденты, таймлайны, интеграции с мониторингами, чатами, постмортемы, подсказки дежурным инженерам. Но довольно быстро стало понятно, что с временными и ресурсными ограничениями лучше не пытаться написать маленький PagerDuty.
Поэтому я сузил задачу до более реалистичного ядра: локального RAG-сервиса, который ищет по документации, ранбукам и коду, а затем передаёт найденный контекст в LLM. Так появился llmortem — FastAPI-сервис, который можно подключить к OpenWebUI как OpenAI-compatible backend. В статье расскажу, как устроена архитектура, почему я начал с BM25, зачем индексировать docstring’и и какие ограничения у такого подхода.
Технические детали
Репозиторий на Гитхабе. В чем вообще проблема? Во время инцидента инженер редко работает с одним источником информации.
Обычно нужно быстро найти и сопоставить:документацию проекта;SRE-документацию;ранбуки;фрагменты кода;логи;метрики;сообщения из чатов;описание релиза. Часть информации уже есть в проекте, но она разбросана по разным файлам и директориям. Например, инструкция по queue lag лежит в ранбуке, описание регистрации — в пользовательской документации, а детали поведения функции — только в docstring’е.
LLM тут кажется хорошим помощником: можно спросить “что делать, если растёт queue lag? ” или “сгенерируй черновик постмортема”. Но если просто отправить вопрос в модель, она не знает внутреннюю документацию проекта и может ответить слишком общо или начать придумывать детали.
Отраслевые последствия
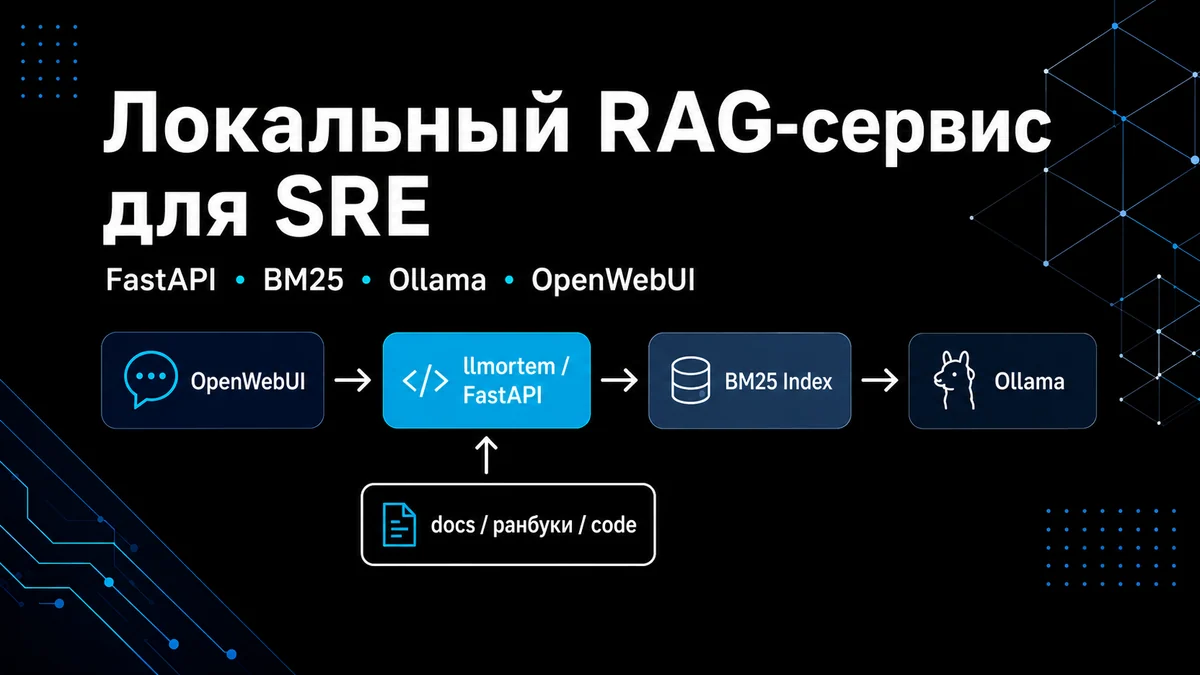
Поэтому вместо обычного “чата с моделью” я сделал RAG-прослойку:пользователь задаёт вопрос;сервис ищет релевантные фрагменты в локальных источниках;найденный контекст добавляется в prompt;prompt отправляется в локальную LLM;пользователь получает ответ, привязанный к материалам проекта. Получилось нечто следующее:llmortem умеет:индексировать Markdown-документацию;индексировать SRE-документацию и ранбуки;извлекать из кода docstring’и, комментарии и сигнатуры;строить BM25-индекс;искать релевантный контекст;определять тип запроса: документационный, SRE/incident или общий;формировать prompt для LLM;обращаться к локальной модели через Ollama;отдавать ответы через OpenAI-compatible endpoint;подключаться к OpenWebUI;генерировать черновик постмортема. Конечно же это не полноценная платформа инцидент-менеджмента.
Тут нет on-call, эскалаций, автоматического таймлайна и интеграций с Grafana/Slack/GitLab. Это именно RAG-ядро, которое можно развивать дальше. АрхитектураОбщая схема выглядит так:Пользователь ↓ OpenWebUI ↓ /v1/chat/completions ↓ FastAPI-сервис llmortem ↓ Intent detection ↓ BM25 retrieval по docs / runbooks / code ↓ Prompt builder ↓ Ollama ↓ Ответ пользователю OpenWebUI ничего не знает о внутренней логике сервиса.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.




