Ранжируем треки с помощью TRIBE и RBF
gCapybara 1 час назад Ранжируем треки с помощью TRIBE и RBF Средний 11 мин 2.6K Python * Машинное обучение * Из песочницы Ощущение — нравится трек или нет, хочется ли его переслушать возникает во время обработки звука...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
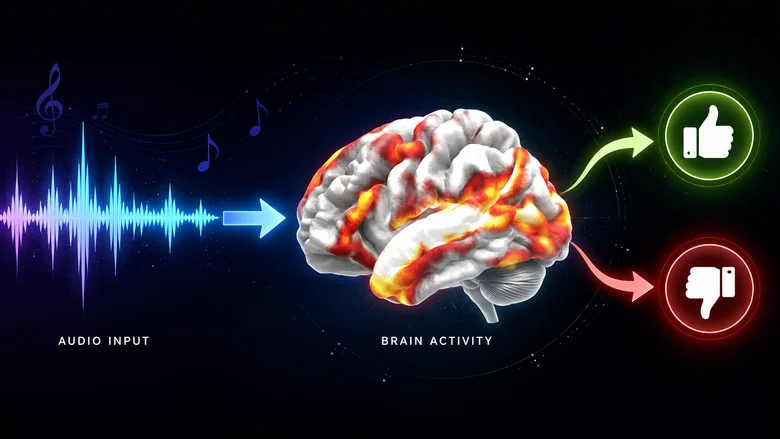
Вот важная новость с фронта ИИ: gCapybara 1 час назад Ранжируем треки с помощью TRIBE и RBF Средний 11 мин 2. 6K Python * Машинное обучение * Из песочницы Ощущение — нравится трек или нет, хочется ли его переслушать возникает во время обработки звука мозгом. Поэтому вместо того, чтобы напрямую предсказывать «качество» музыки по спектрограммам или эмбеддингам, можно построить промежуточное представление: сначала оценить, какие паттерны активности коры вызывает аудио, а затем уже по этим паттернам предсказывать относительную популярность треков.
Для предсказания активности коры использовалась нейросеть TRIBE. TRIBE — это модель brain encoding: она получает стимул и предсказывает, какой отклик он вызовет в коре головного мозга. Изначально TRIBE работает с видео и объединяет три потока признаков — текст, изображение и звук.
Технические детали
В этой статье используется только аудио: аудио файл превращается в последовательность векторов, описывающих на предсказанную активность коры. Практически это означает следующее. На вход подаётся аудио файл, на выходе - матрица:где T — число временных фрагментов, а D — число признаков корковой активности.
D составляет порядка 20 тысяч, где каждое значение соответствует активности определенного участка коры. Таким образом, один трек превращается в динамику предсказанной реакции мозга по мере звучания музыки. В качестве исходных данных используется Free Music Archive (далее FMA): это открытый датасет для задач Music Information Retrieval: классификации жанров, рекомендаций, поиска похожей музыки, анализа метаданных.
Полная версия FMA содержит больше 100 тысяч треков, но в эксперименте использовался вариант small: 8000 mp3-фрагментов по 30 секунд, 8 сбалансированных жанров. Для этой задачи важен не жанр, а поля из tracks. csv: идентификатор трека, идентификатор альбома и число прослушиваний.
Идея эксперимента такая: если TRIBE действительно сохраняет в своих выходах часть информации о том, как звук обрабатывается мозгом, то в этих признаках может быть слабый сигнал, связанный с тем, какой трек слушатели выбирают чаще. Поставим задачу так: взять два трека из одного альбома и предсказать, какой из них набрал больше прослушиваний. Заметим, что сравнение происходит именно внутри одного альбома — прослушивания плохо сравниваются между разными артистами и релизами: у одного исполнителя 10 тысяч прослушиваний могут быть провалом, у другого — верхней границей аудитории.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.




