От Naive RAG до ReAct-агента: как мы строили корпоративного AI-помощника на open-source моделях (часть 1)
chestny_znak 9 часов назад От Naive RAG до ReAct-агента: как мы строили корпоративного AI-помощника на open-source моделях (часть 1) Простой 15 мин 6.4K Блог компании 43Tech Искусственный интеллект Open source * Natural...
Anthropic — What company has the best second artificial intelligence model at the end of June?
В сфере искусственного интеллекта произошло заметное событие. chestny_znak 9 часов назад От Naive RAG до ReAct-агента: как мы строили корпоративного AI-помощника на open-source моделях (часть 1) Простой 15 мин 6. 4K Блог компании 43Tech Искусственный интеллект Open source * Natural Language Processing * Обзор Привет, Хабр! Меня зовут Константинов Александр, я — старший AI-инженер в Лаборатории искусственного интеллекта «Честного знака».
Наша команда развивает «Честного помощника» — мультиагентную LLM-систему для обработки документов, поиска информации по Confluence, Jira, GitLab и генерации текстов. Главная цель команды — повышать эффективность и качество работы сотрудников за счёт расширения числа специализированных агентов в нашей мультиагентной системе. Но давайте будем честны: мы начинали с решения совсем другой задачи.
Технические детали
Терминология на тот момент была ещё сырой и непроверенной, рынок open-source решений оставлял желать лучшего — мы выжимали максимум из того, что было доступно. Поэтому дальнейший рассказ будет полезен широкой аудитории: от тех, кто только начинает разбираться в теме, до руководителей отделов, которые хотят внедрить подобное решение у себя. Это первая часть из двух.
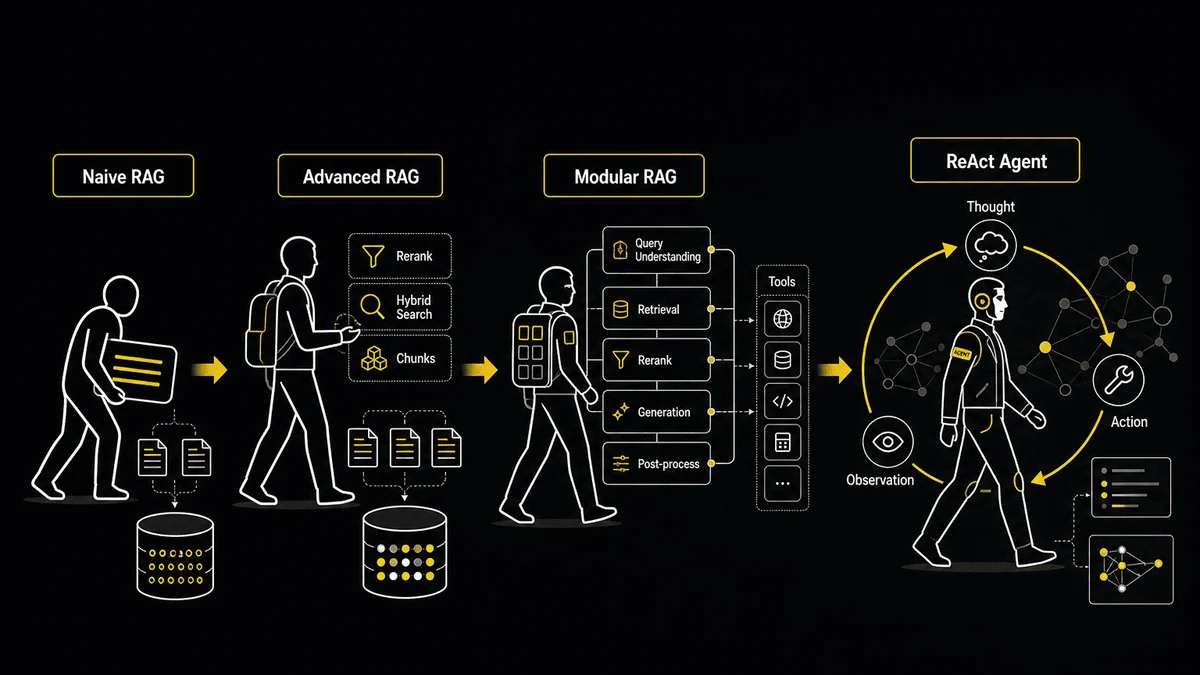
Здесь мы разберём ключевые понятия, а затем подробно пройдём весь путь создания MVP на базе Naive RAG — от индексации документов до первых ответов в продакшене и осознания, что этого недостаточно. Во второй части перейдём к Advanced RAG, мультиагентной архитектуре, ReAct-агенту и качественному тестированию. Основная терминология и понятияLLM — это категория «фундаментальных» моделей, обученных на огромных объёмах данных, что позволяет им понимать и генерировать естественный язык и другие виды контента, а также выполнять широкий спектр задач.
Токен – это единица текста, например слово или часть слова, которой присвоен уникальный числовой идентификатор. LLM-модели используют такие числовые представления, чтобы эффективно обрабатывать и «понимать» текст. Для расчета токенов используется модель-токенизатор от LLM, которая преобразует текст в токены.
Отраслевые последствия
Контекст — это набор токенов, которые LLM обрабатывает за один проход вперёд (forward pass). Он формирует основу для ответа модели. Контекстное окно — это максимальное количество токенов, которое модель способна воспринять за один раз.
Ограничение длины окна влияет на то, сколько информации можно включить в один запрос. Галлюцинация — это когда модель генерирует убедительный, но ложный или неподтверждённый текст. Ответ может выглядеть правдоподобно, но не основан на фактах или не соответствует запросу.
Open source LLM — это модели, которые доступны для свободного использования и модификации. Они не имеют лицензионных ограничений и могут быть использованы в коммерческих проектах. Наиболее популярные open source LLM: QwenDeepseekMistral (отдам дань уважения :D)Давайте подробнее остановимся на проблеме галлюцинаций.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.