# pg-smart-search: Путь от 8 секунд до 40 мс — Часть 2. Масштабирование до миллиона строк и производственная архитектура
Привет, Хабр!В первой части мы разобрали архитектуру pg-smart-search изнутри: параллельный Promise.race, механизм Zombie Prevention через AbortSignal, адаптерный паттерн и CLI-инструмент. Если не читали -- рекомендую...
Anthropic — What company has the best second artificial intelligence model at the end of June?
В сфере искусственного интеллекта произошло заметное событие. В первой части мы разобрали архитектуру pg-smart-search изнутри: параллельный Promise. race, механизм Zombie Prevention через AbortSignal, адаптерный паттерн и CLI-инструмент. Если не читали -- рекомендую начать оттуда, здесь я буду отсылать к тем концепциям.
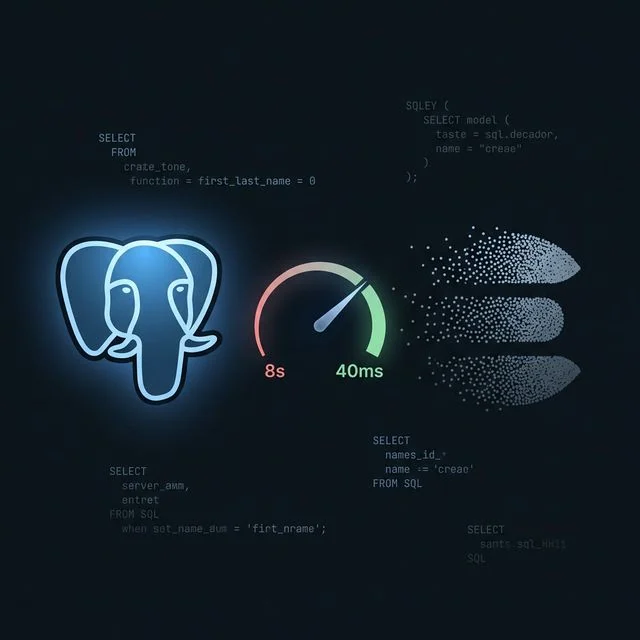
В этой части речь пойдет о том, что происходит, когда ты запускаешь всё это на реальных данных. На объемах до 100K строк система работала именно так, как задумано: FTS побеждал в Promise. race первым, кэш давал sub-1ms на горячих запросах, пропускная способность — 90 req/sec.
Технические детали
1 000 000 строк с нормальным, реальным словарем — и всё сломалось. Время поиска улетело к 8-ми секундам. В этой статье - честный разбор двух этапов спасения: сначала архитектурные фиксы, потом бой с «ошибками выжившего» в бенчмарках.
И в конце — production-grade микрооптимизации, которые мы сделали в v1. 1, вылизав каждую миллисекунду.
Событие, по словам экспертов, усилит конкуренцию в сфере ИИ.





