AI для PHP-разработчиков. Часть 6: Bag of Words и TF–IDF – как компьютер превращает текст в математику
samako 12 минут назад AI для PHP-разработчиков. Часть 6: Bag of Words и TF–IDF – как компьютер превращает текст в математику Средний 10 мин 296 PHP * Машинное обучение * Data Mining * Алгоритмы * Поисковые технологии *...
Anthropic — What company has the best second artificial intelligence model at the end of June?
В сфере искусственного интеллекта произошло заметное событие. samako 12 минут назад AI для PHP-разработчиков. Часть 6: Bag of Words и TF–IDF – как компьютер превращает текст в математику Средний 10 мин 296 PHP * Машинное обучение * Data Mining * Алгоритмы * Поисковые технологии * Аналитика Как компьютер превращает текст в числа и почему TF–IDF десятилетиями оставался основой поисковых систем. Разбираем Bag of Words, TF–IDF и поиск похожих документов на чистом PHP.
Это шестая часть проекта. Часть 5: От массивов к GPU: как PHP-экосистема приходит к настоящему MLЧасть 4: Практическое использование TransformersPHPЧасть 3: Практика без Python и data scienceЧасть 2: Собираем простейшую RAG-систему на PHP с Neuron AI за вечерЧасть 1: Как я пытался подружить PHP с NER – драма в 5 актахКогда мы говорим, что нейросети "понимают текст", легко забыть одну важную вещь: компьютер изначально вообще не умеет понимать слова. Для машины текст – это просто последовательность символов.
Технические детали
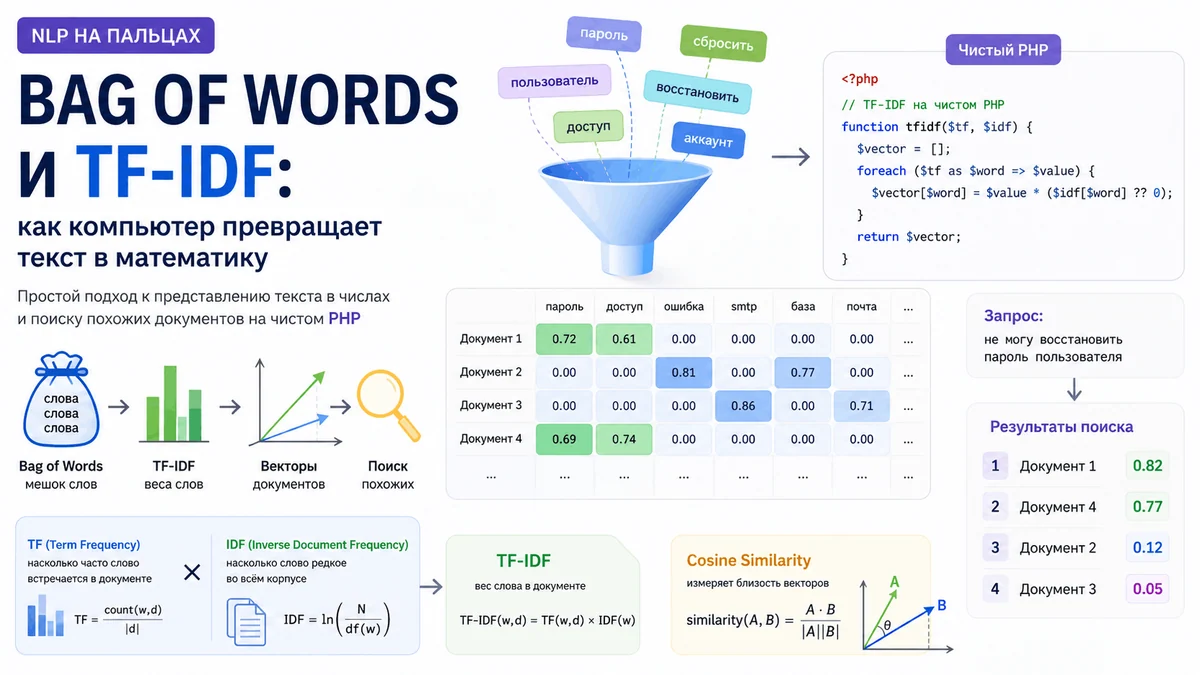
Чтобы алгоритмы могли работать с языком, текст нужно превратить в числа. Именно здесь появляются Bag of Words и TF–IDF – два фундаментальных подхода, с которых исторически начиналось NLP и поиск по тексту. Несмотря на возраст, эти методы до сих пор используются:в поисковых системах;в FAQ и helpdesk;в корпоративных поисковиках;в рекомендациях документов;в классификации текстов.
И главное – они помогают понять, как вообще текст становится математикойИсторическая справкаИсторически эти подходы появились в разные годы и развивались постепенно. Bag of Words начал формироваться ещё в 1950-х годах как простой способ представления текста через набор слов. Активно развиваться этот подход стал в 1960-х вместе с работами Жерара Салтона и появлением vector space model.
TF–IDF появился позже - в начале 1970-х. Идею IDF предложила Карен Спэрк Джонс в 1972 году, а затем TF–IDF стал популярным благодаря исследованиям Жерара Салтона в области информационного поиска. Bag of Words: "мешок слов"BOW - Bag of Words (мешок слов) – это способ представить текст без учёта порядка слов.
Отраслевые последствия
Нас интересует только то, какие слова встретились и сколько раз. Представим два предложения:"Кот ест рыбу""Рыбу ест кот"Для человека они почти одинаковы. Для Bag of Words – абсолютно одинаковы.
Мы как бы высыпаем слова из текста в мешок, перемешиваем, забывая об их порядке и считаем количество каждого слова. Как строится словарьПервый шаг – построить словарь. Это просто список всех уникальных слов во всех документах.
Пусть у нас есть три документа:D1: кот ест рыбу D2: кот любит рыбу D3: собака ест мясоСначала строится словарь всех уникальных слов:После этого каждому слову назначается индекс:кот → 0 ест → 1 рыбу → 2 любит → 3 собака → 4 мясо → 5Превращаем текст в векторТеперь каждый документ можно представить как числовой вектор длины |V|, где |V| – размер словаря.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.





