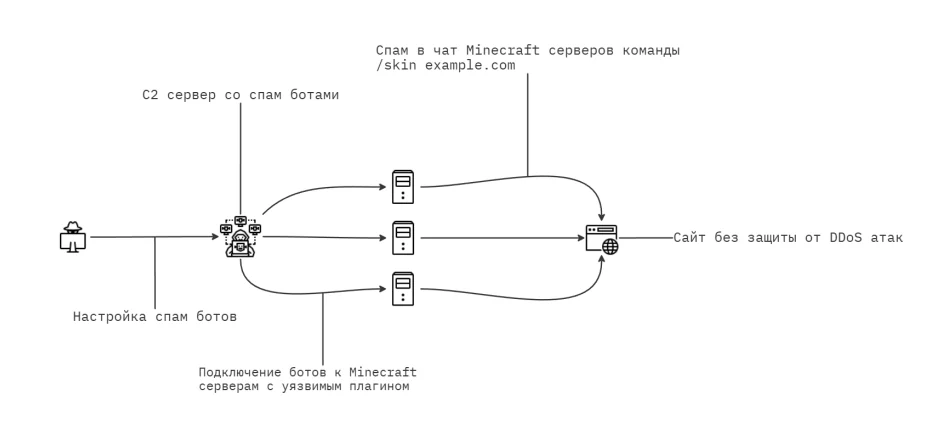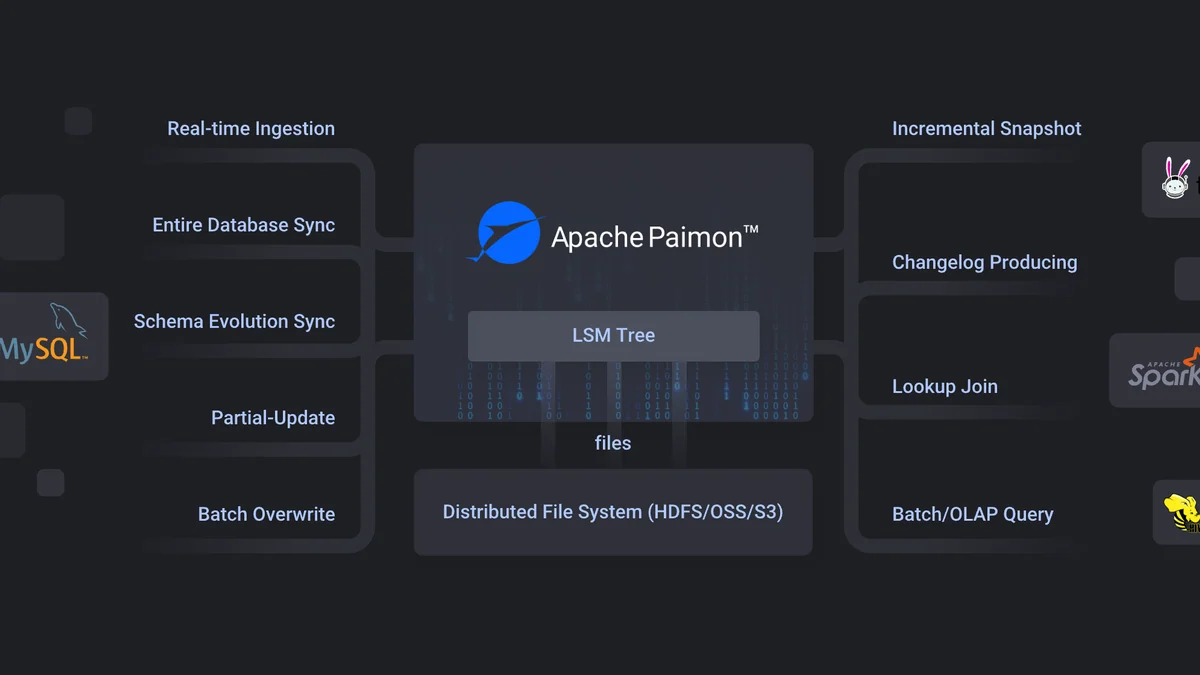
Apache Paimon: steamhouse как логическое продолжение современных КХД
alealandreev 10 минут назад Apache Paimon: steamhouse как логическое продолжение современных КХД Средний 45 мин 150 Data Engineering * Big Data * Java * SQL * Processing * Обзор Всем привет! Меня зовут Александр...
<5 — 2026'da uzaya kaç SpaceX Starship fırlatması ulaşacak?
Вот важная новость с фронта ИИ: alealandreev 10 минут назад Apache Paimon: steamhouse как логическое продолжение современных КХД Средний 45 мин 150 Data Engineering * Big Data * Java * SQL * Processing * Обзор Всем привет! Меня зовут Александр Андреев, я ведущий инженер данных в департаменте машинного обучения компании "АльфаСтрахование". Я люблю изучать новые и перспективные технологии в сфере обработки и хранения данных, а еще больше я люблю рассказывать о них коллегам и внедрять их в рабочие процессы.
В этой статье я хочу сделать обзор не совсем новой, но при этом перспективной опенсорс-технологии хранения данных - Apache Paimon. Мы пройдемся детально от возникновения потребности в streamhouse-подходе к хранению данных и основ Apache Paimon до сравнительных бенчмарков с другими подходами к хранению данных и примеров кода. Возможно, именно эта технология подойдет вашей компании для того, чтобы наконец "поженить" батч со стримингом.
Технические детали
Введение: эволюция хранения данных и текущие вызовыДавайте представим современную data-платформу крупной компании. С одной стороны, у вас есть системы, генерирующие непрерывный поток событий: клики пользователей, транзакции, логи сервисов. С другой стороны, аналитики и дата-сайентисты ждут свежие данные для построения отчетов и обучения моделей.
Между системами и людьми традиционно стоит сложная инфраструктура из множества компонентов: Kafka для потоковой передачи, Flink или Spark Streaming для обработки, HDFS или S3 для хранения, и наконец, хранилище данных вроде ClickHouse или Snowflake для аналитики. Каждый переход между компонентами добавляет задержку. Каждая система требует своего формата данных.
Каждое преобразование может привести к потере консистентности. В результате получается то, что в индустрии называют "data swamp" - болото данных, где простой вопрос "какие данные у нас актуальные? " превращается в настоящий детектив.
Отраслевые последствия
Apache Paimon появился как попытка решить эту фундаментальную проблему, объединив лучшее из двух подходов: эффективность потоковой обработки и надежность батч-систем. Но чтобы понять, почему это важно, давайте сначала разберемся с корнем проблемы. Корень проблемы: почему streaming и batch живут раздельноИсторически сложилось так, что системы для обработки потоков и пакетной обработки развивались независимо, решая разные задачи.
Потоковые системы оптимизировались для минимальной задержки - получил событие, обработал, отправил дальше. Их главная метрика успеха - это latency (задержка), то есть время от появления данных до получения результата. Пакетные системы, напротив, оптимизировались для максимальной пропускной способности - собрал большой объем данных, эффективно обработал все разом.
Их метрика - throughput (пропускная способность), то есть количество данных, обработанных за единицу времени. Эти различия привели к совершенно разным архитектурным решениям. Потоковые системы хранят данные в append-only логах, где новые записи просто добавляются в конец.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.