Невидимый враг многопоточности: False Sharing и кэш-линии процессора
anton_dolganin 17 минут назад Невидимый враг многопоточности: False Sharing и кэш-линии процессора Средний 3 мин 250 Системное программирование * C * C++ * Алгоритмы * Обзор Представьте типичную ситуацию: вы...
Anthropic — What company has the best second artificial intelligence model at the end of June?
В сфере искусственного интеллекта произошло заметное событие. anton_dolganin 17 минут назад Невидимый враг многопоточности: False Sharing и кэш-линии процессора Средний 3 мин 250 Системное программирование * C * C++ * Алгоритмы * Обзор Представьте типичную ситуацию: вы оптимизируете высоконагруженный бэкенд или сетевой сервис. И абсолютно неважно, на чем вы пишете — C++, Java, Go или C#. У вас есть несколько потоков, и вы решаете избавиться от медленных блокировок.
Ведь мьютексы — это узкое горлышко, верно? Вы применяете классический паттерн: вместо того чтобы потоки толкались локтями вокруг одной переменной, вы даете каждому потоку (или горутине) свой собственный, независимый счетчик. Нет общих данных — нет конфликтов.
Технические детали
Вы запускаете нагрузочные тесты, ожидая увидеть красивое линейное ускорение, но профилировщик показывает странное. Потоки словно продолжают стоять в очереди, а код на многоядерной машине начинает работать едва ли не медленнее, чем на одном ядре. Как такое возможно, если блокировок в коде больше нет?
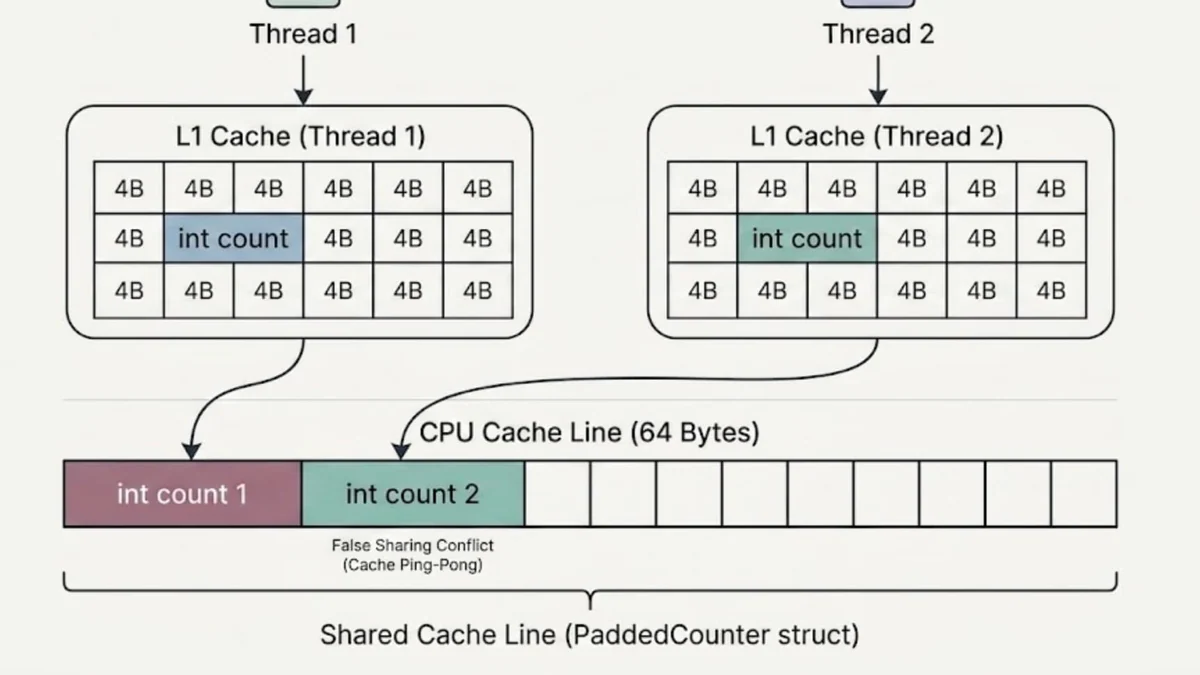
Добро пожаловать в реальный мир, где абстракции вашего языка программирования разбиваются о суровое железо. Проблема в том, что процессору глубоко все равно на то, как вы логически разделили переменные в коде. Виной всему False Sharing (ложное разделение) — невидимая аппаратная блокировка.
Чтобы понять, почему ваш идеальный lock-free код тормозит, нам придется заглянуть под капот и посмотреть, как процессор на самом деле читает память. Кэш-линии: Как процессор видит памятьЭтот раздел можете скипнуть, если вы знаете про кэш-линии. Процессор никогда не читает память по одному байту.
Отраслевые последствия
Это слишком медленно. Вместо этого он загружает данные целыми блоками — кэш-линиями. В современных архитектурах размер одной кэш-линии обычно составляет 64 байта.
Если процессору нужна переменная размером 4 байта, он заберет ее вместе с соседними 60 байтами и положит в свой кэш. Как устроена иерархия памяти по времени доступа (этот самый кэш), упрощенно:L1-кэш (у каждого ядра свой — и это ключевой момент для нас): самый быстрый (~1 наносекунда), но маленький (обычно 32–64 КБ на данные). L2-кэш (у каждого ядра свой): чуть медленнее (~4 наносекунды), побольше (256 КБ – 1 МБ).
L3-кэш (общий на весь процессор): медленный (~15-20 наносекунд), но объемный (десятки мегабайт). Оперативная память (RAM): «черепаха» по меркам процессора (~100 наносекунд). Кстати, я в свое время запомнил эти уровни кеша как: карманы (L1), рюкзак (L2), схрон или склад (L3), другой город (RAM).
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.





