Извлечение и обработка требований из документов с помощью NLP-инструментов
Avlakan 37 минут назад Извлечение и обработка требований из документов с помощью NLP-инструментов Простой 13 мин 1.4K Блог компании АСКОН Python * Программирование * Кейс Приветствую всех читателей Хабр.Думаю, многим...
Anthropic — What company has the best second artificial intelligence model at the end of June?
В сфере искусственного интеллекта произошло заметное событие. Avlakan 37 минут назад Извлечение и обработка требований из документов с помощью NLP-инструментов Простой 13 мин 1. 4K Блог компании АСКОН Python * Программирование * Кейс Приветствую всех читателей Хабр. Думаю, многим знаком этот сценарий: появляется задача — и первая мысль: «скормлю все LLM, она разберётся».
Поначалу получается красиво, всё работает и есть первые результаты. Потом начинаешь проверять детали и замечаешь, что модель местами добавляет текст от себя. Потом смотришь на затрачиваемое время и понимаешь, что при текущей скорости обработка всего объёма документов закончится через год.
Технические детали
Именно в такой ситуации я оказался, когда захотел обработать базу ГОСТов. Эта статья — про то, как я прошёл путь от «кидаем всё в LLM» до детерминированного пайплайна на классических NLP-инструментах. И про то, как в этом помогли те же самые языковые модели — но уже в роли консультантов, а не рабочей лошадки.
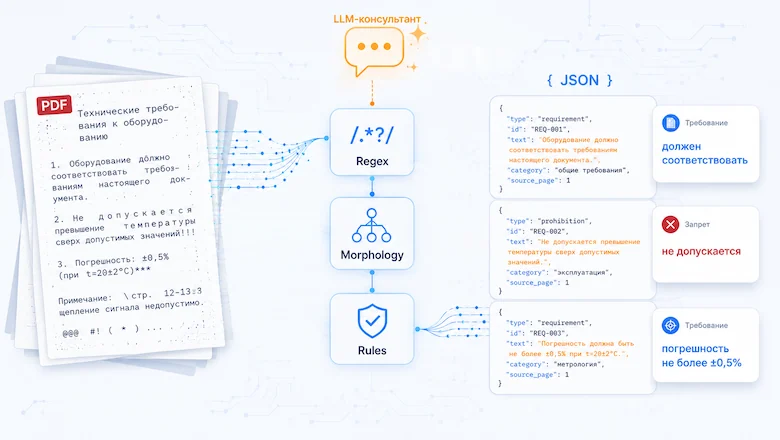
ЗадачаВ архиве лежало порядка 54 тысяч PDF-файлов — ГОСТы и другие нормативные документы. Нужно было найти в них текстовые фрагменты, похожие на требования, извлечь их и зафиксировать с указанием конкретного раздела, откуда они были взяты. В качестве среды для эксперимента я использовал n8n.
Он удобен тем, что содержит множество готовых узлов для работы как с данными, так и с AI-агентами. Кроме того, на каждом шаге запуска можно посмотреть, что происходит с данными, увидеть входящий и исходящий JSON и быстро подправить алгоритм работы цепочки в случае необходимости. Для задач, где много итераций и гипотез, это сильно ускоряет работу.
Отраслевые последствия
Конфигурация стенда выглядела так: 2 x GPU серии RTX 5060 с 16 ГБ памяти, модель Qwen3-30B A3B Q6K, запущенная локально через LM Studio. Я планировал быстро собрать рабочую цепочку и запустить обработку всего массива документов, и в целом задача выглядела несложно, но дьявол, как обычно, кроется в деталях. 0: «скормим всё в LLM»Первая реализация цепочки выглядела предельно просто:Забираем PDF из хранилища (у меня это был S3-совместимый storage)Извлекаем текст с помощью стандартной ноды Extract From FileГотовим и предварительно фильтруем текстПередаём в LLM с инструкцией извлечь требования в JSON (рабочий промпт получился достаточно большой, он разрабатывался и дорабатывался с помощью LLM)Собираем результат.
Первая же проблема вскрылась на этапе извлечения текста. При обработке PDF на выходе получался текст с целым зоопарком артефактов:слова с разрывами посередине: рас-\nщепление, при-\nмерслова, сформированные через пробел: т е м п е р а т у р ы«поехавшие» дефисы, превратившиеся в минусы или тиреслучайные символы от артефактов сканированиянарушенный порядок колонок в многоколоночных документах. По идее, текст нужно было нормализовать до передачи в модель: почистить, склеить, восстановить структуру.
Но, как это часто бывает, я решил пойти по более короткому пути — «LLM всё поймёт» — и отправлял текст как есть.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.





