Некорпоративный Хабр: семантический поиск и фильтрация по структурированным полям в браузере (wllama и duckdb wasm)
Классический RAG индексирует исходный текст документа, предварительно разбивая на фрагменты. Потом рассчитывает векторное представление фрагментов и сохраняет их векторные представления в базу данных для поиска. Это...
Anthropic — What company has the best second artificial intelligence model at the end of June?
В сфере искусственного интеллекта произошло заметное событие. Классический RAG индексирует исходный текст документа, предварительно разбивая на фрагменты. Потом рассчитывает векторное представление фрагментов и сохраняет их векторные представления в базу данных для поиска.
Это дает возможность искать по сходству фрагментов текста и поискового запроса пользователя, но не дает возможность искать по более высокоуровневым резюме и смыслам, темам поднятым в тексте и прочему. Также не помогает с аналитикой по содержимому.
Технические детали
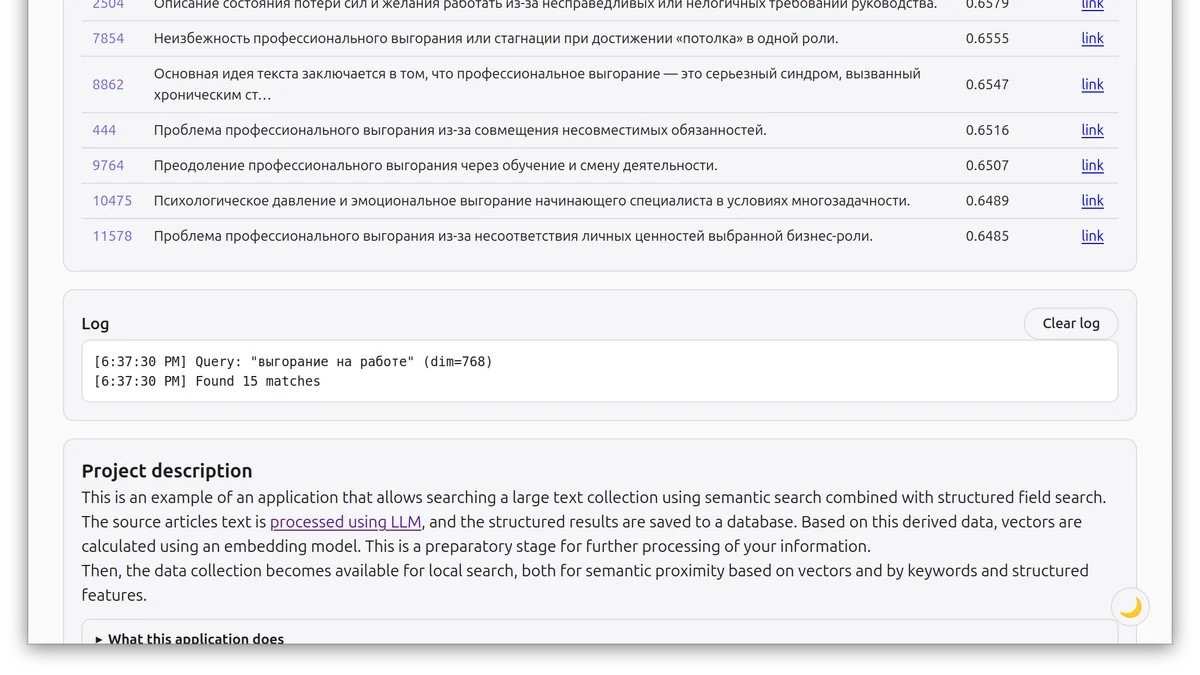
Бесплатный проект text-metadata-generator позволяет выполнять запросы к LLM по каждому документу из коллекции документов, результаты вывода LLM проверяются по JSON схеме. Зачем может пригодиться эта программа и подход со структурированием текстовой информации:Если нужна своя библиотека с каталогом - поиск по локальным документам с использованием комбинации SQL предикатов и семантического поискаАналитика по документам, возможность находить новое в текстах: комбинируя структурированные поля созданные LLM из исходного текста, и находя закономерности с уже существующими в документе метаданными.
Например, связывая с рейтингом признак NSFW, тон повествования, полноту содержания итп.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.





