YARL: как мы развиваем распределённый Rate Limiter
ivavse 24 минуты назад YARL: как мы развиваем распределённый Rate Limiter 11 мин 48 Блог компании Yandex Cloud & Yandex Infrastructure Высоконагруженные системы * IT-инфраструктура * Серверное администрирование *...
Anthropic — What company has the best second artificial intelligence model at the end of June?
В сфере искусственного интеллекта произошло заметное событие. ivavse 24 минуты назад YARL: как мы развиваем распределённый Rate Limiter 11 мин 48 Блог компании Yandex Cloud & Yandex Infrastructure Высоконагруженные системы * IT-инфраструктура * Серверное администрирование * Привет, это Всеволод Иванов и Артём Икчурин из Yandex Infrastructure — в нашей инфраструктурной команде Cloud Storage Services мы занимаемся разработкой хранилищ, которые внутри компании используются самыми разными сервисами. В Яндексе есть несколько систем хранения для разных задач, в том числе объектное хранилище для неструктурированных данных. Несколько лет назад мы искали способы ограничить нагрузку на внутренний сервис S3 — так появилось наше собственное решение Yet Another Rate Limiter, или YARL, о котором мы уже писали на Хабре.
Сегодня расскажем, как развивается наш лимитер. Так что если вам интересны высокие нагрузки, рекомендуем ознакомиться с предыдущей статьёй и затем вместе с нами отправиться под кат за продолжением. Что важно помнить про YARL Освежим в памяти несколько ключевых моментов из прошлой серии, про которые важно знать для понимания последующей истории:В нашем хранилище сейчас находится несколько эксабайт данных (1018 Б), и в пиках мы обрабатываем несколько миллионов RPS‑запросов от внешних клиентов Яндекса.
Технические детали
Квота — это сущность, описывающая ресурс, который мы потребляем. Она содержит параметры лимитирования: лимит, который указывает, сколько событий мы можем обрабатывать в секунду для этого ресурса. Ещё есть два дополнительных параметра, которые называются low burst и high burst, и используются для вероятностного лимитирования.
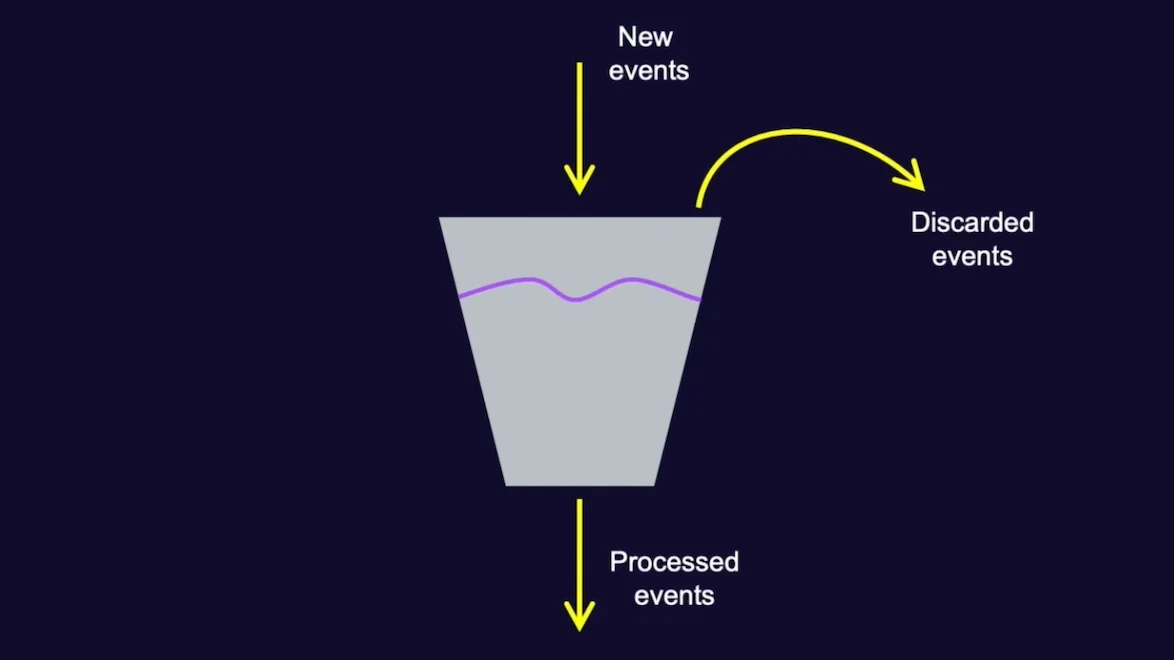
Счётчик — это просто число, нужное для того, чтобы считать потребление квот. Это временная сущность, она живёт в памяти приложений, создаётся, когда квоты начинают использоваться, и удаляется, когда квоты больше не используются. Квоты работают на базе алгоритма Leaky Bucket.
В каждой статье, которую вы откроете с описанием этого алгоритма, будет нарисовано ведро, в которое сверху наливается вода. В основе архитектуры сервиса находится мультимастер рутов, который обеспечивает отказоустойчивость. Руты — это сервисы, выступающие точками правды о том, что же происходит на кластере, которые хранят у себя потребление всех квот, созданных в системе.
Отраслевые последствия
Каждый клиент синхронизируется с каждым рутом. Для хранения персистентных данных, а именно параметров квот, которые мы создавали, у нас есть база данных, она позволяет не терять их между рестартами приложений и рутов. Ещё один кубик в нашей схеме — это агрегатор.
Он выступает посредником между клиентами и рутами, чтобы разгрузить последние от слишком большого количества запросов.
Этот прогресс даёт важные сигналы о будущем отрасли, и технологический мир внимательно наблюдает.





